avro格式定义如下图: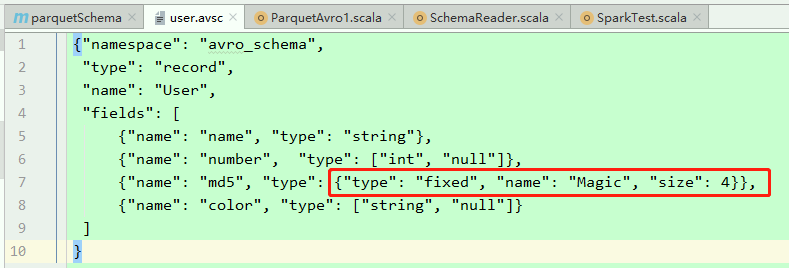
然后spark正常读取生成的parquet则报错:Illegal Parquet type: FIXED_LEN_BYTE_ARRAY。问怎么读取parquet(不一定要用spark)?详细错误如下:
org.apache.spark.sql.AnalysisException: Illegal Parquet type: FIXED_LEN_BYTE_ARRAY;
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.illegalType$1(ParquetSchemaConverter.scala:107)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convertPrimitiveField(ParquetSchemaConverter.scala:175)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convertField(ParquetSchemaConverter.scala:89)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.$anonfun$convert$1(ParquetSchemaConverter.scala:71)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at scala.collection.TraversableLike.map(TraversableLike.scala:237)
at scala.collection.TraversableLike.map$(TraversableLike.scala:230)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convert(ParquetSchemaConverter.scala:65)
at org.apache.spark.sql.execution.datasources.parquet.ParquetToSparkSchemaConverter.convert(ParquetSchemaConverter.scala:62)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.$anonfun$readSchemaFromFooter$2(ParquetFileFormat.scala:664)
at scala.Option.getOrElse(Option.scala:138)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.readSchemaFromFooter(ParquetFileFormat.scala:664)
at org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.$anonfun$mergeSchemasInParallel$2(ParquetFileFormat.scala:621)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2(RDD.scala:801)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2$adapted(RDD.scala:801)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)

spark读取avro序列化的parquet时报错:Illegal Parquet type: FIXED_LEN_BYTE_ARRAY

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
 大大怪打LZR 2023-08-13 21:49关注
大大怪打LZR 2023-08-13 21:49关注根据您提供的错误信息,似乎问题出在Parquet文件的数据类型不匹配上。Parquet文件中的数据类型与读取器(例如Spark)期望的数据类型不一致。
根据您的问题描述,您的Avro架构定义中可能使用了
FIXED数据类型,而这在Parquet文件中通常对应于FIXED_LEN_BYTE_ARRAY类型。然而,Spark 默认情况下可能不支持直接将 Parquet 文件中的FIXED_LEN_BYTE_ARRAY数据类型映射到 Spark 数据类型。为了解决这个问题,您可以考虑以下几种方法:
自定义Schema映射: 尝试使用自定义的Schema映射来将 Parquet 文件中的
FIXED_LEN_BYTE_ARRAY数据类型转换为Spark支持的数据类型。您可以通过在读取Parquet文件时提供一个自定义的Schema来实现这一点。升级Spark版本: 有时候问题可能是特定版本的Spark引起的,尝试升级到较新的Spark版本可能会解决某些问题,因为Spark不断在版本中改进Parquet读写支持。
数据转换: 在读取Parquet文件之前,将其转换为适合Spark的数据格式,例如CSV或JSON。然后,您可以使用Spark读取这些转换后的文件。
Parquet工具: 使用Parquet文件的命令行工具,例如Apache Parquet Tools,可以提供关于Parquet文件的更多信息,有时可以揭示出数据类型不匹配的问题。
最好的方法可能会取决于您的具体情况。您还可以根据具体的Avro架构和Parquet文件内容,尝试调整Schema映射或转换数据格式以解决问题。
解决 无用评论 打赏举报 分享
- 2017-08-07 02:38回答 2 已采纳 已经找到解决办法。还是因为对API不熟造成的。avro 有方法能够解析无scheam的文件。前提是在类方法中指定一个scheam进行解析。 大致方法如下。 public static List
- 2021-02-14 17:26回答 1 已采纳 看看这个: https://blog.csdn.net/wangshuminjava/article/details/80179648
- 2016-11-11 13:20回答 2 已采纳 Just found out (by comparing binary avro messages) that I had to remove the first 5 elements of th
- 2021-06-12 21:03Spark 与 Avro 和 Parquet 随附一个简单的 Spark 应用程序,演示如何以 Parquet 和 Avro 格式读取和写入数据。 Avro 指的是二进制格式和内存中的 Java 对象表示。 Parquet 仅指一种二进制格式,它支持可插入的内存...
- 2023-03-24 23:50回答 1 已采纳 根据您提供的信息,我们可以初步分析出可能出现错误的步骤:1. AvroSource的配置是否正确,包括IP地址、端口号等信息是否正确设置;2. Flume的配置是否正确,包括source、channe
- 2018-10-26 15:48回答 1 已采纳 The panic is probably coming from a nil pointer reference to the job variable. I would suggest in
- 2022-05-12 09:10回答 1 已采纳 进入目录bin/flume-ng赋权chmod +x flume-ng
- 2021-01-12 02:00游戏干线的博客 [返回Spark教程首页]Spark SQL可以支持Parquet、JSON、Hive等数据源,并且可以通过JDBC连接外部数据源。前面的介绍中,我们已经涉及到了JSON、文本格式的加载,这里不再赘述。这里介绍Parquet,下一节会介绍JDBC...
- 2021-12-01 16:09回答 2 已采纳 File does not exist: hdfs://localhost:9000/usr/local/sqoop/lib/parquet-avro-1.4.1.jar 你最后一行不是有提示了么,文
- 回答 1 已采纳 metadata就是元数据,用来存放表结构、字段信息之类的,用来描述数据的数据。另外eclipse也有自己的metadata,你要看看是哪个metadata缺失了。
- 2016-10-17 02:31回答 1 已采纳 在eclipse中 配置spring 自定义的schema文件 问题:使用了spring自定义schema时,在xml文件中无法自动提示自定义的tag。 解决:在eclipse中设置:
- 2021-05-15 17:25使用Apache Flink处理Apache Parquet文件此仓库包含用于设置Flink数据流以处理Parquet文件的示例代码。 resources/下的CSV数据集是从下载的Restaurant Score数据集。 有关更多信息,请参见。 ###生成Avro模型类如果...
- 2014-05-12 09:38回答 3 已采纳 通过这段 [quote] Current thread (0x00007f4b4c070000): VMThread [stack: 0x00007f4b486f7000,0x00007f4b4
- 2021-02-03 21:07schemer:CSV,TSV,JSON,AVRO和Parquet架构的架构注册表。 支持模式推断和GraphQL API
- 2022-04-23 13:17Maven坐标:org.apache.parquet:parquet-avro:1.10.0; 标签:apache、parquet、avro、jar包、java、API文档、中文版; 使用方法:解压翻译后的API文档,用浏览器打开“index.html”文件,即可纵览文档内容。 人性化...
- 2021-03-26 20:55支持以下数据导入格式:[Apache Avro] [avro], 和 。 允许从导入数据。 支持将表以Apache Parquet格式导出到公共云存储系统。 支持以下云存储系统: , , , 和。 允许配置并行的导入或导出过程。 用户须知 ...
- 2021-05-14 19:46ABRiS-适用于Spark的Avro Bridge 无痛Spark / Avro集成。... 在Spark 2.3.x上,您必须声明对org.apache.avro:avro:1.8.0或更高版本的依赖。 (Spark 2.3.x使用Avro 1.7.x,因此您必须将其覆盖,因为ABRiS
- 入门:你会发现一个Jupyter笔记本电脑,介绍了轰隆隆的顶部JSONiq语言。 您可以通过安装多合一数据科学平台来使用它,除非您更喜欢手动安装Python + Spark + PySpark + Jupyter(brew,apt ...)。 该文档还包含...
- 没有解决我的问题, 去提问



悬赏问题
- ¥35 平滑拟合曲线该如何生成
- ¥100 c语言,请帮蒟蒻写一个题的范例作参考
- ¥15 名为“Product”的列已属于此 DataTable
- ¥15 安卓adb backup备份应用数据失败
- ¥15 eclipse运行项目时遇到的问题
- ¥15 关于#c##的问题:最近需要用CAT工具Trados进行一些开发
- ¥15 南大pa1 小游戏没有界面,并且报了如下错误,尝试过换显卡驱动,但是好像不行
- ¥15 自己瞎改改,结果现在又运行不了了
- ¥15 链式存储应该如何解决
- ¥15 没有证书,nginx怎么反向代理到只能接受https的公网网站