
这时我学习的代码是这样的
public void process(Page page) {
page.putField("articleURL",page.getUrl().toString());
page.putField("articleTitle",page.getHtml().xpath("//a[@class=\"titlelnk\"]").toString());
if(page.getResultItems().get("articleTitle")== null){
page.setSkip(true);
}
page.addTargetRequests(
page.getHtml().xpath("//div[@id=\"post_list\"]").links().regex("https://www.cnblogs.com/[a-z A-Z 0-9 -]+/p/.+.html").all()
);
}
我想提取网页中的a标签中的这段文字,数据总共有20个,如下图: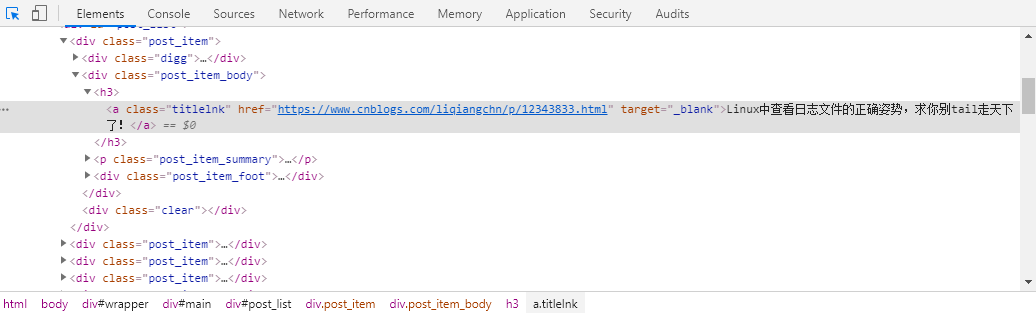
但是提取出来的数据只有第一个
而且articleURL属性也出现了错误,也查了一天半也不知道怎么解决。




