请教大家一个反爬虫问题, 七麦是如何实现反爬虫的?
目标网址: https://www.qimai.cn/search/index/country/cn/search/王者荣耀
使用Jsoup.connect(url).get()获取不到页面数据的。只返回head 、body数据。

请教大家一个反爬虫问题, 七麦是如何实现反爬虫的?
目标网址: https://www.qimai.cn/search/index/country/cn/search/王者荣耀
使用Jsoup.connect(url).get()获取不到页面数据的。只返回head 、body数据。
 分享
分享
浏览器抓包,看一下,是另一个请求获取的数据,而不是直接通过七麦的网址,它是动态加载的并没有通过这个网址获取数据,而是另一个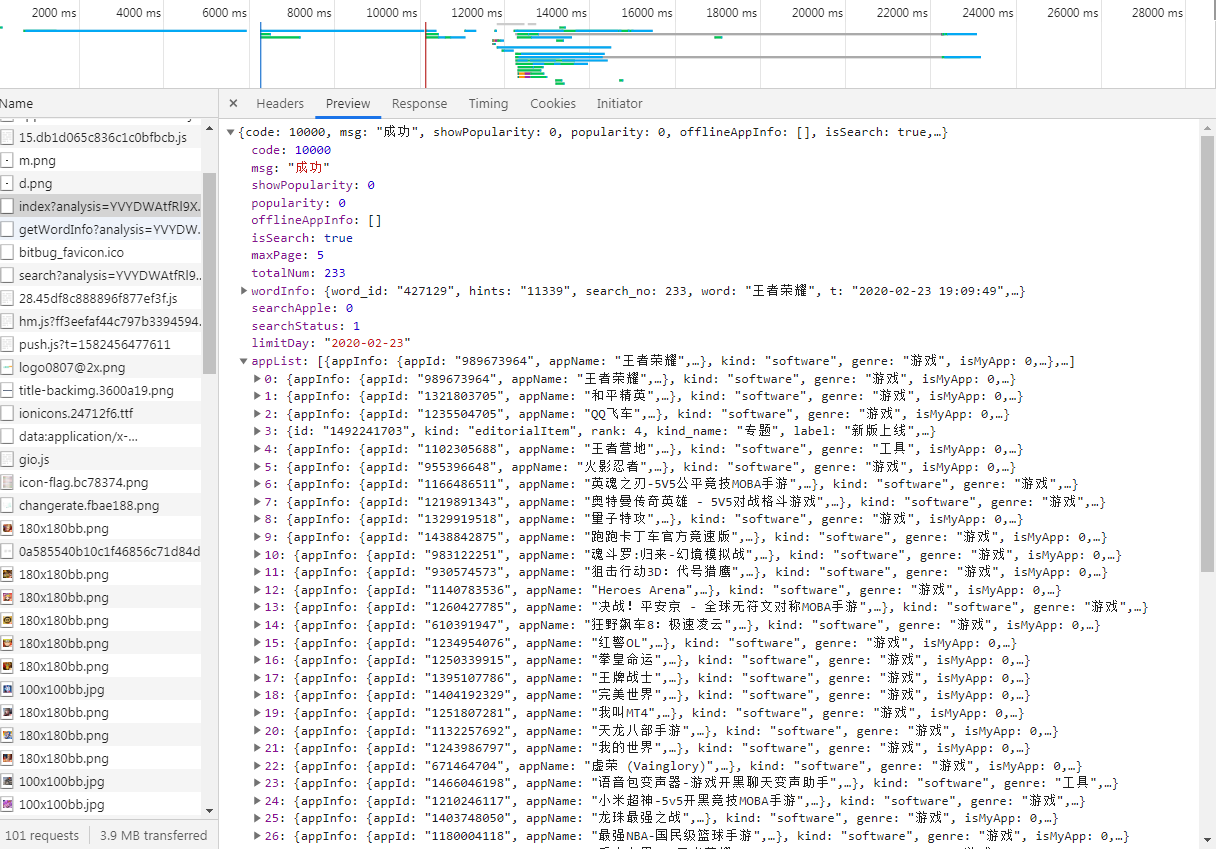
分享



