
这是参考书上的代码
import urllib.request
url='https://www.baidu.com/'
response=urllib.request.urlopen(url,timeout=3)
print('获取url信息:',response.geturl()) #返回response的url信息
print('获取返回代码:',response.getcode()) #返回response的状态代码
print('获取返回信息:',response.info()) #返回response的基本信息
result=response.read().decode('utf-8')
print(result)
with open('baidu.txt','w',encoding='utf-8') as abc:
abc.write(result)
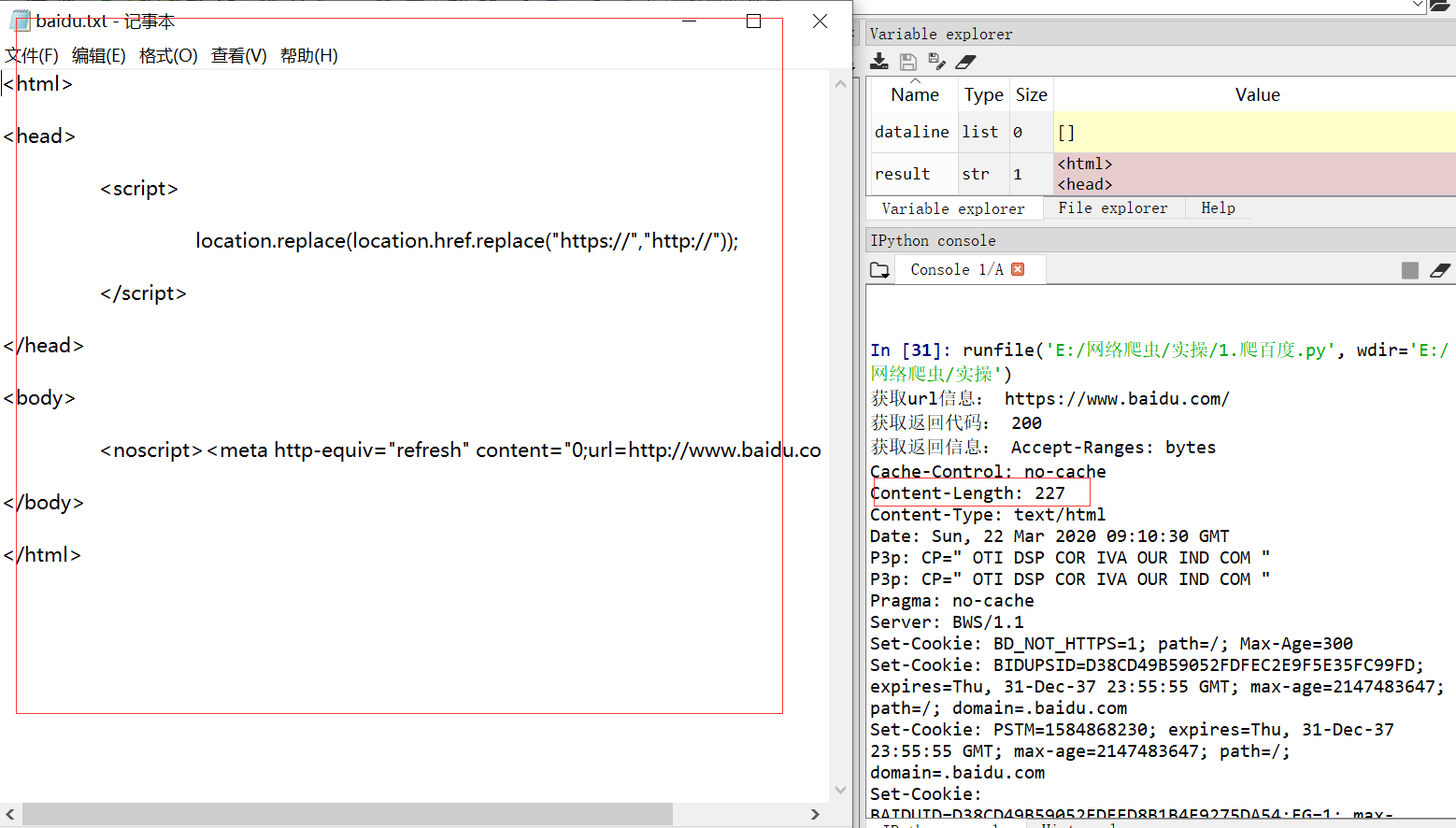
文本中应该有227长,但实际文本缺少了很多东西,求解答!!谢谢



