
报错信息如下: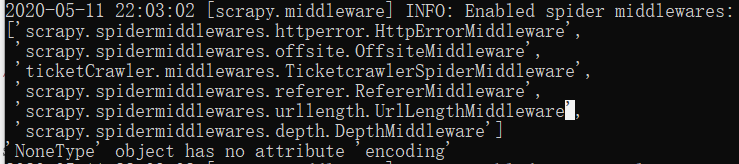
scrapy中的spider代码如下:
import scrapy
from scrapy import Request,Spider
from ticketCrawler.items import TicketCrawlerItem
from scrapy.selector import Selector
import sys
from lxml import etree
#from calculate import calculatePageNumber
import re
class ticketSpider(scrapy.Spider):
#爬虫标识,用于区分不同的spider
name="ticketCrawler"
start_url = ['https://www.chinaticket.com/']
urls = {
'yanchanghui':'https://www.chinaticket.com/wenyi/yanchanghui/',
'huaju':'https://www.chinaticket.com/wenyi/huaju/',
'yinleju':'https://www.chinaticket.com/wenyi/yinyueju/',
'xiqu':'https://www.chinaticket.com/wenyi/xiqu/',
'baleiwu':'https://www.chinaticket.com/wenyi/baleiwu/',
'qinzijiating':'https://www.chinaticket.com/wenyi/qinzijiating/',
'zaji':'https://www.chinaticket.com/wenyi/zaji/',
'xiangshengxiaopin':'https://www.chinaticket.com/wenyi/xiangshengxiaopin/'
}
def start_requests(self):
try:
for key,value in self.urls.items():
yield Request(value.encode('utf-8'),meta={'type':key.encode('utf-8')},callback = self.parse)
except Exception as err:
print(err)
def get_next_url(self):
try:
pass
except Exception as err:
print(err)
def parse(self,response):
try:
item = TicketCrawlerItem()
meta = response.meta() #概要 meta标签提供关于HTML文档的元数据
result = response.text.encode("utf-8")
if result==''or result=='None':
print("can't get the sourceCode")
sys.exit()
tree = etree.HTML(result)
data = []
page = tree.xpath("//*[@class='s_num']/text()")[1].replace("\n","").replace('','').encode("utf-8")
calculateNum = calculatePageNumber()
pageNUM = calculateNum.calculate_page_number(page)
count = (pageNUM/10)+1
listDoms = tree.xpath("//*[@class='s_ticket_list']//ul")
if(listDoms):
for itemDom in listDoms:
item['type'] = meta['type'].encode('utf-8')
try:
titleDom = itemDom.xpath("li[@class='ticket_list_tufl']/a/text()")
if(titleDom[0]):
item['name'] = titleDom[0].encode("utf-8")
except Exception as err:
print(err)
try:
urlDom = itemDom.xpath("li[@class='ticket_list_tufl']/a/@href")
if(urlDom[0]):
item['url'] = urlDom[0].encode("utf-8")
except Exception as err:
print(err)
try:
timeDom = itemDom.xpath("li[@class='ticket_list_tufl']/span[1]/text()")
if(timeDom[0]):
item['time'] = timeDom[0].encode("utf-8").replace('时间:','')
except Exception as err:
print(err)
try:
addressDom = itemDom.xpath("li[@class='ticket_list_tufl']/span[2]/text()")
if(addressDom[0]):
item['address'] = addressDom[0].encode("utf-8").replace('地点:','')
except Exception as err:
print(err)
try:
priceDom = itemDom.xpath("li[@class='ticket_list_tufl']/span[3]/text()")
if(priceDom[0]):
item['time'] = priceDom[0].encode("utf-8").replace('票价:','')
except Exception as err:
print(err)
yield item
for i in range(2,count+1):
next_page = "https://www.chinaticket.com/wenyi/"+str(meta['type'])+"/?o=2&page="+str(i)
if next_page is not None:
yield scrapy.Request(next_page,meta={"type":meta['type']},callback = self.parse)
except Exception as err:
print(err)
class calculatePageNumber():
def calculate_page_number(self,page):
try:
result = re.findall(r"\d+\.?\d*",page)
return int(result[0])
except Exception as err:
print(err)






