\x08是退格键,一个字符串如果有\x08,decode时会删除前一个字符,请问如何解决?
比如:
s = b'abc\x08de'
print(s.decode())
输出:abde
c被删除了。
用requests从网上抓取数据,遇到这个字符,导致html标签的>被删除,无法正常解析。如下图,这个名字里有\x08,content里的a标签有右>,text里的就没有了。请问如何解决?
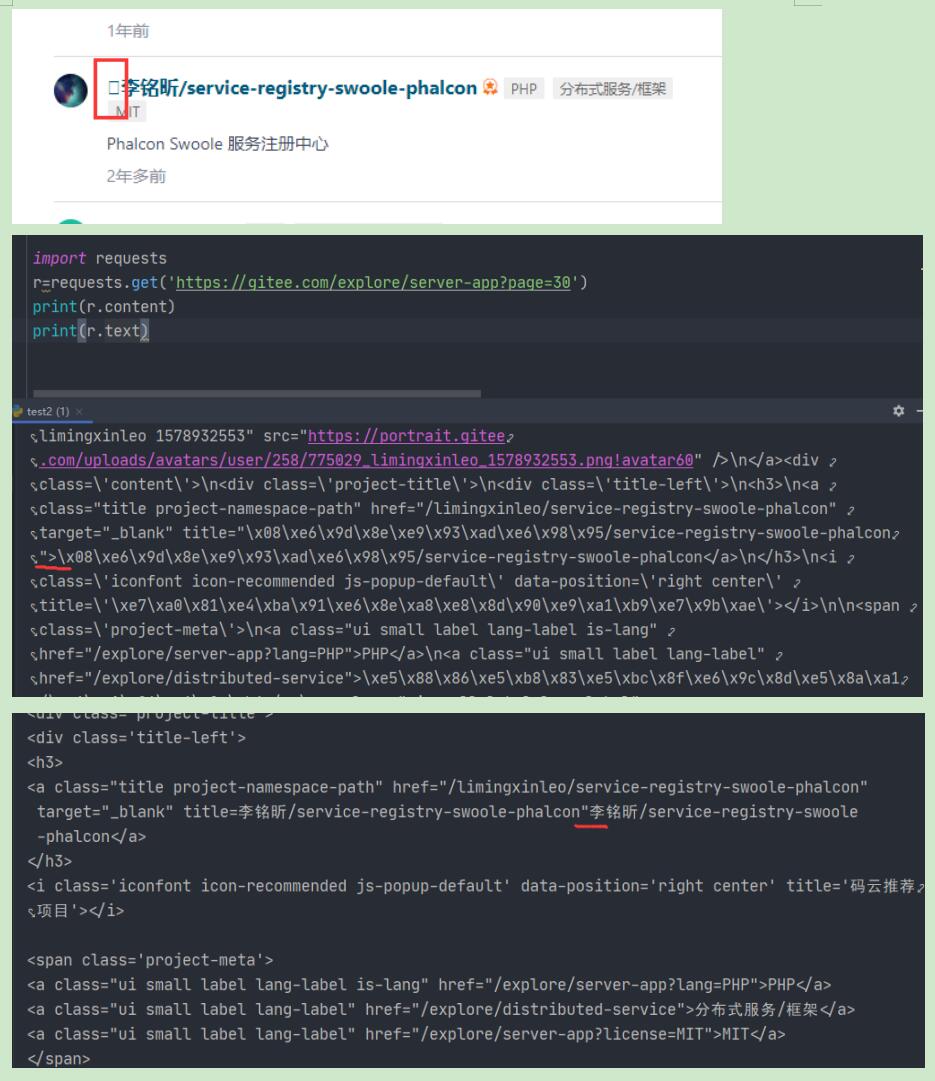

\x08是退格键,一个字符串如果有\x08,decode时会删除前一个字符,请问如何解决?
比如:
s = b'abc\x08de'
print(s.decode())
输出:abde
c被删除了。
用requests从网上抓取数据,遇到这个字符,导致html标签的>被删除,无法正常解析。如下图,这个名字里有\x08,content里的a标签有右>,text里的就没有了。请问如何解决?
 分享
分享
import re
s = re.compile('[\\x00-\\x08\\x0b-\\x0c\\x0e-\\x1f]').sub(' ', str)
用正则表达式过滤乱码字符。
来源:
分享




