
使用爬虫获取在线学习网站课件,目的是通过课程列表url,获取所有课程的课件。由于页面使用Angular实现页面跳转,所以在分析网页源码和异步加载时找不到课件的courseID。前期分析结果如下:
1.课程列表界面和源码
https://nbcb.scho.com:8020/pc/#/scho_home/column_detail?columnId=16132 #课程列表url,通过此链接获取所有课件
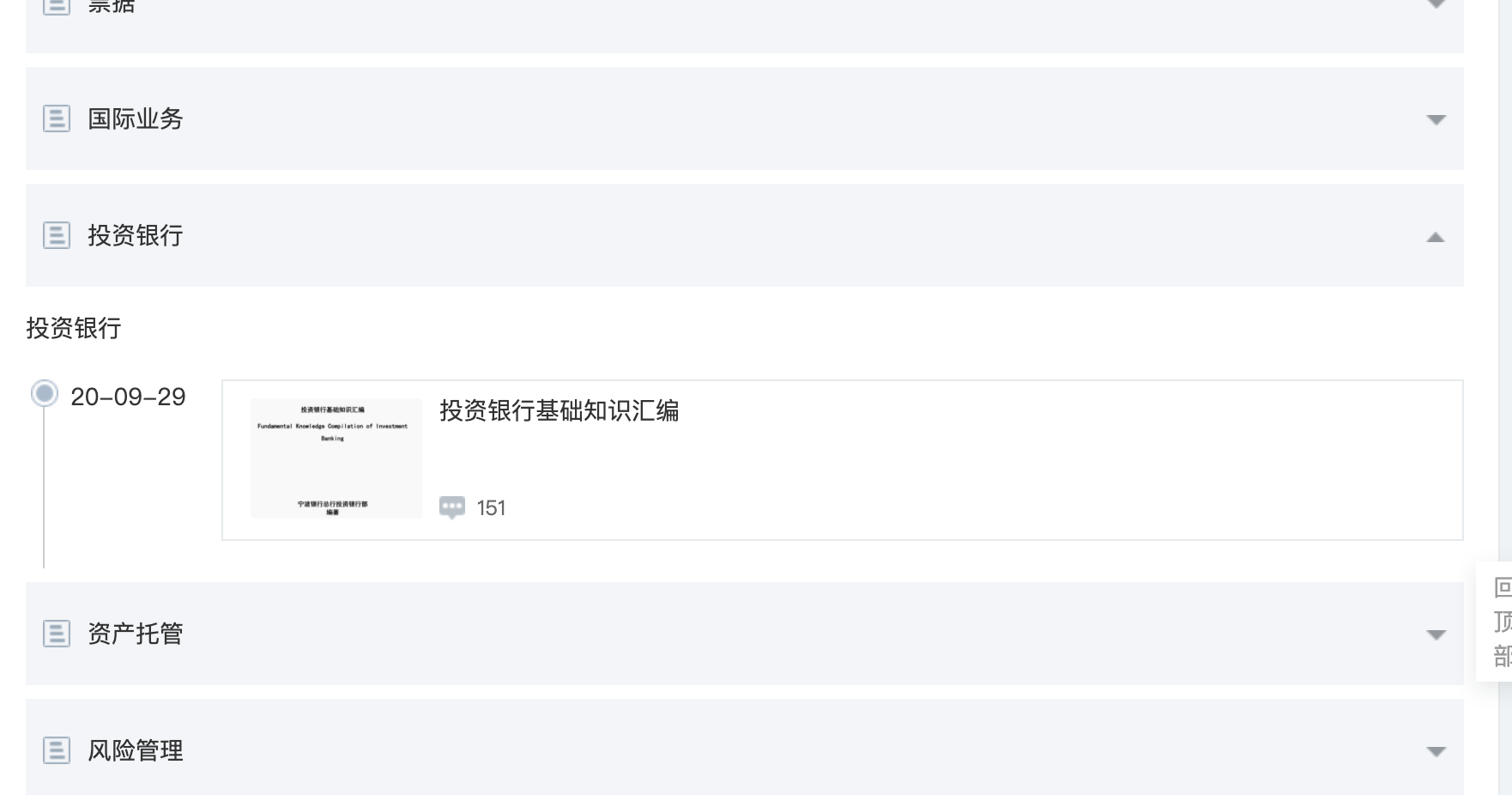
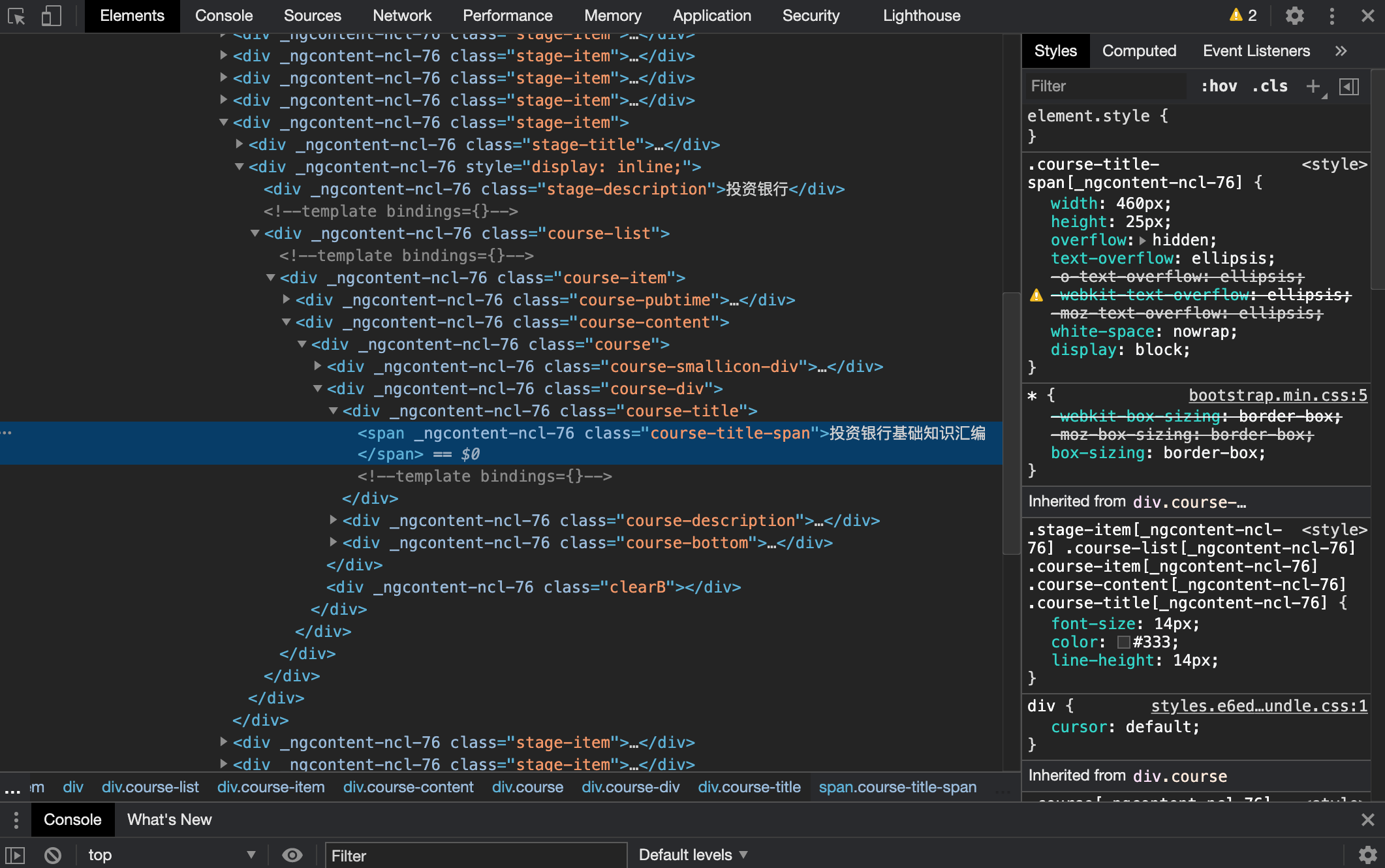
2.点击课程列表界面的具体课件,鼠标未变成小手一样的图标,仍然是一个箭头。进入点击后进入课件界面:
`
https://nbcb.scho.com:8020/pc/#/scho_home/column_detail #课件界面url未发生变化
`

3.课件界面所有http请求如下:
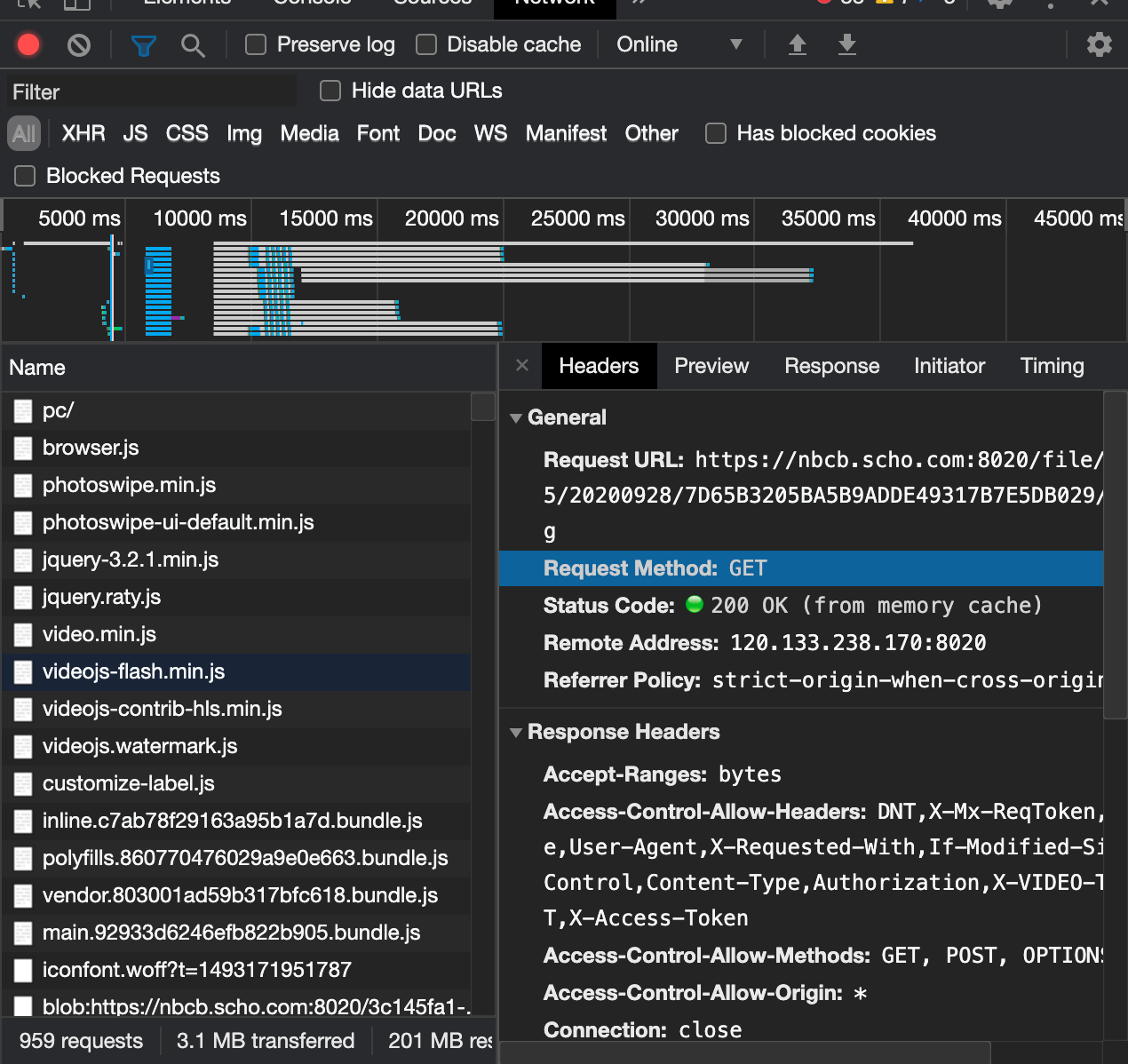
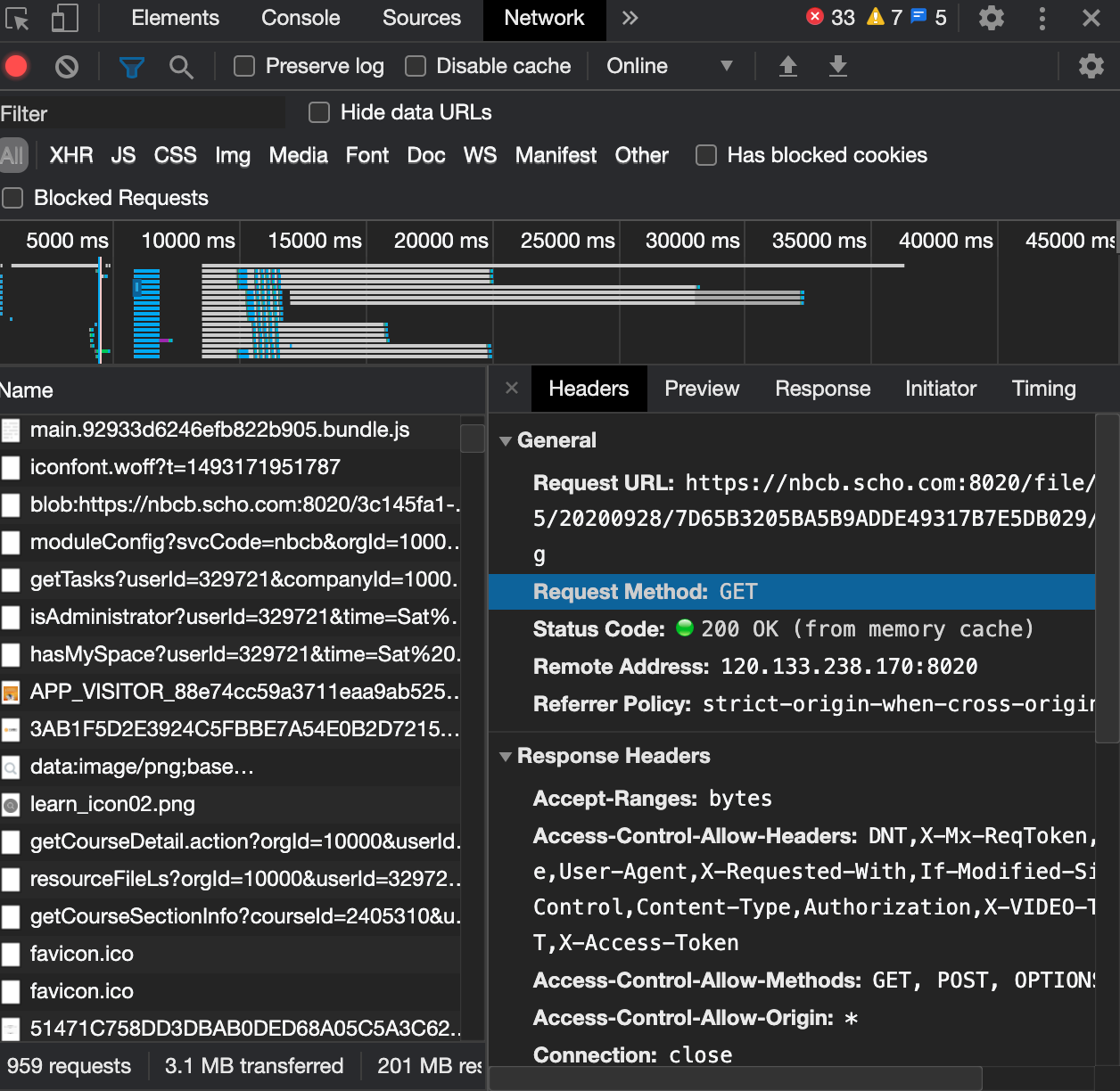
4.使用浏览器开发者工具找到目标文件是通过获取图片来组成课件,URL长这样:
https://nbcb.scho.com:8020/file/nbcb/310685/20200928/7D65B3205BA5B9ADDE49317B7E5DB029/out//70.jpg
5.通过页面源代码解析,未找到课程的id:7D65B3205BA5B9ADDE49317B7E5DB029。
但getCourseDetail请求链接的参数中有个CourseID=2405310,返回Json数据中包含7D65B3205BA5B9ADDE49317B7E5DB029。






