
事情是这样的,我想写个小程序爬取路由器上设备带宽。网址上逻辑是这样的(每次刷新访问都是如下过程):
1.打开网址会先显示,正在加载,如下图(图片查看不了访问:http://picture.daemon.cool/view.php?p=16067035224537)

2.过大概一秒左右,进入业务页面,显示设备名称及带宽(图片查看不了访问:http://picture.daemon.cool/view.php?p=16067035223159):
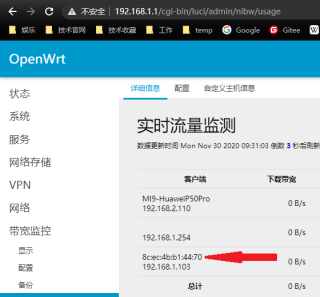
我本人写的代码爬去设备的mac地址:
#!/usr/bin/python
# coding=utf-8
import requests,time
s=requests.session()
data = {
'luci_username': 'root',
'luci_password': 'password',
}
res = s.post('http://192.168.1.1', data)
while True:
print(res.status_code)
var = s.get(url='http://192.168.1.1/cgi-bin/luci/admin/nlbw/usage', ).content.decode('utf-8')
if var.find("8c:ec:4b:b1:44:70") >= 0:
print("8c:ec:4b:b1:44:70")
if var.find("正在加载") >= 0:
print("正在加载")
打印结果:
200
正在加载
200
正在加载
200
正在加载
200
正在加载
200
正在加载
200
求问,基于我的代码,如何爬取到第二个页面中的MAC地址,或者说如何持续爬一个有加载过程的页面?







