拿新闻系统来说。一条新闻对应多个分类,正常来讲表设计为一对多的关系,3张→新闻表,分类表,新闻分类关联表。随着时间的推移,新闻越来越多,表中的数据越来越大。查询起来会越来越慢。程序要求能够按照多个分类(or的关系)、标题、地区等去搜索新闻、分页。如何设计这个系统的表结构才能使得搜索高效快速?(分类均为五位数的ID),新闻内容需要格式,html代码,需要什么类型?与新闻表分离还是在一起呢?目前数据量200w+。
旧的程序设计是只有一张新闻表,分类单独一个字段,分类字段数据用逗号隔开‘10001,10002,10012’这种,新改版后需要多个条件搜索,按目前200w左右的数据like查询,三个分类or的关系查询都得个4s甚至更多,实在接受不了。该如何设计?如果现有的表结构不改变该如何优化?求解~~~
SQL Server

sql数据库设计,一对多的问题。数据量在200w+,求设计思路

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新
 threenewbee 2016-02-10 22:33关注
threenewbee 2016-02-10 22:33关注可以分库,比如分为历史库和当前库。对于历史库的内容,直接缓存静态页面。不必要再查询。
另外不知道你like是什么?全文搜索么?全文搜索需要建立全文索引(对于中文,还有一个分词的步骤)。而不是这么like解决 无用评论 打赏举报 分享
- 2015-11-10 06:45回答 3 已采纳 inner join查出来,每条都带有作者信息,需要你自己合并成前台需要的数据结构 或者,先查出作者,然后ajax去请求每个作者的作品,然后填充
- 2022-03-31 17:24回答 5 已采纳 其实没有实际的标准明确定义多少数据量算大数据,不过阿里开发手册中建议,表数据超过500万条时,建议考虑分表,以防影响查询效率,不过我们公司也有单表超过几千万条的数据,效率确实不高,所以理论上百万级别以
- 2017-12-18 03:54回答 8 已采纳 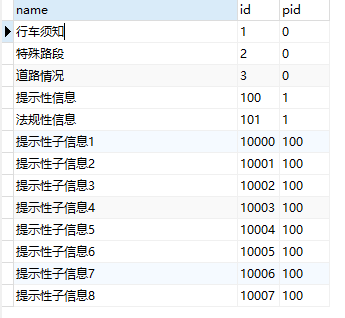 ``` SELECT * FROM `table
- 2019-06-26 14:22科技D人生的博客 一、基础规范 (1)必须使用InnoDB存储引擎 解读:支持事务、行级锁、并发性能更好、CPU及内存缓存页优化使得资源利用率更高 (2)新库使用utf8mb4字符集 解读:万国码,无需转码,无乱码风险,节省空间 (3)...
- 2018-04-28 03:39回答 2 已采纳 http://www.phpdb.net/records/item/59.html https://blog.csdn.net/marko39/article/details/52187506
- 2015-11-07 04:03回答 7 已采纳 我根据你的描述提取了这些关键词 单位 职位 是否在岗 岗位级别 调入所在地 调出所在地 离职(就是那个人不存在),领导总数 每个级别总数 哪个职位少人 你看看这些哪些是实体
- 2019-09-10 13:36回答 4 已采纳 你在存储过程中就要对查询出来的结果进行处理,构成grid需要的数据格式;或者接口返回数据后,在前端对数据进行处理,然后在grid中渲染出来。
- 2021-06-22 00:32ITFLY8的博客 一、什么是大数据平台一般情况下,大数据平台指的是使用了Hadoop、Spark、Storm、Flink、Blink等这些分布式、实时或者离线计算框架,并在上面运行各种计算任务的平台。建设大...
- 2017-12-11 09:23回答 6 已采纳 参考一下: 分组后排序,赋值rownum,然后取rownum=1,就是要保留的一组, 最后删除除此之外的所有数据。 ``` delete * from MyTable b where
- 2015-06-11 03:10回答 4 已采纳 计划任务,设置增量备份即可。
- 2016-08-11 04:28回答 1 已采纳 就这两张表啊 应该很好关联吧,你思路也很清晰也很好查
- 2022-01-18 19:38过往记忆的博客 1 什么是数据倾斜数据倾斜即指在大数据计算任务中某个处理任务的进程(通常是一个JVM进程)被分配到的任务量过多,导致任务运行时间超长甚至最终失败,进而导致整个大任务超长时间运行或者失败。外...
- 2020-06-29 22:15回答 3 已采纳 代码有两个地方有问题,for循环最终输出的sql是一条记录的脚本,row是执行的影响行数,row==3改成row>0即可 ``` 可以for循环构造insert into批量插入语句,
- 2022-02-16 19:19回忆de天空的博客 数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜,存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作,...
- 2023-06-28 09:12java李杨勇的博客 Python是由荷兰数学和计算机研究学会的吉多•范罗苏姆于20世纪90年代设计的一款高级语言。Python优雅的语法和动态类型,以及解释型语言的本质,使它成为许多领域脚本编写和快速开发应用的首选语言。Python相比与其他...
- 没有解决我的问题, 去提问


悬赏问题
- ¥30 python代码,帮调试
- ¥15 #MATLAB仿真#车辆换道路径规划
- ¥15 java 操作 elasticsearch 8.1 实现 索引的重建
- ¥15 数据可视化Python
- ¥15 要给毕业设计添加扫码登录的功能!!有偿
- ¥15 kafka 分区副本增加会导致消息丢失或者不可用吗?
- ¥15 微信公众号自制会员卡没有收款渠道啊
- ¥100 Jenkins自动化部署—悬赏100元
- ¥15 关于#python#的问题:求帮写python代码
- ¥20 MATLAB画图图形出现上下震荡的线条