
python做爬虫时,如何获取下一页的html?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新

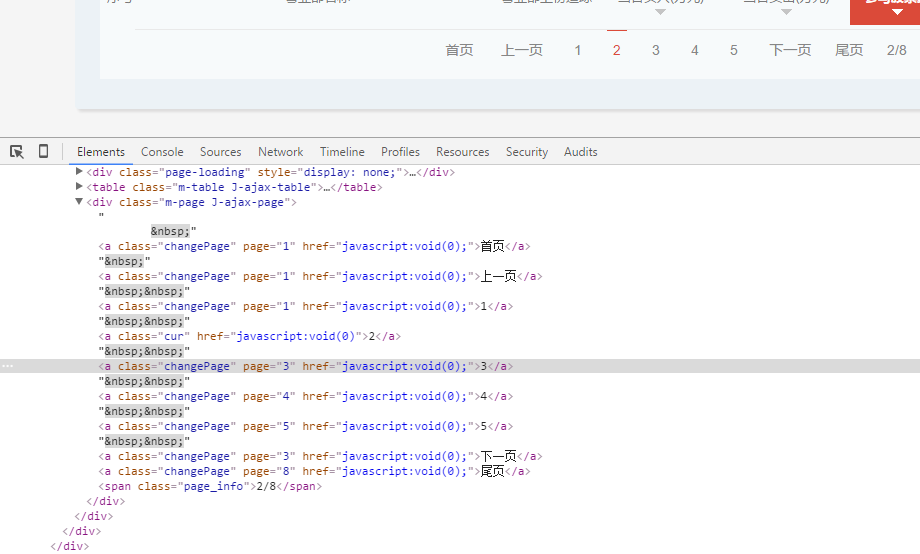](http://data.10jqka.com.cn/market/yybhyd/!%5B%E5%9B%BE%E7%89%87%E8%AF%B4%E6%98%8E%5D(https://img-ask.csdn.net/upload/201603/09/1457522333_494323.png)){kind=link}
问题事件
 提问应符合社区要求
11月30日
提问应符合社区要求
11月30日
悬赏问题
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 对于相关问题的求解与代码
- ¥15 ubuntu子系统密码忘记
- ¥15 信号傅里叶变换在matlab上遇到的小问题请求帮助
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作
- ¥15 求NPF226060磁芯的详细资料