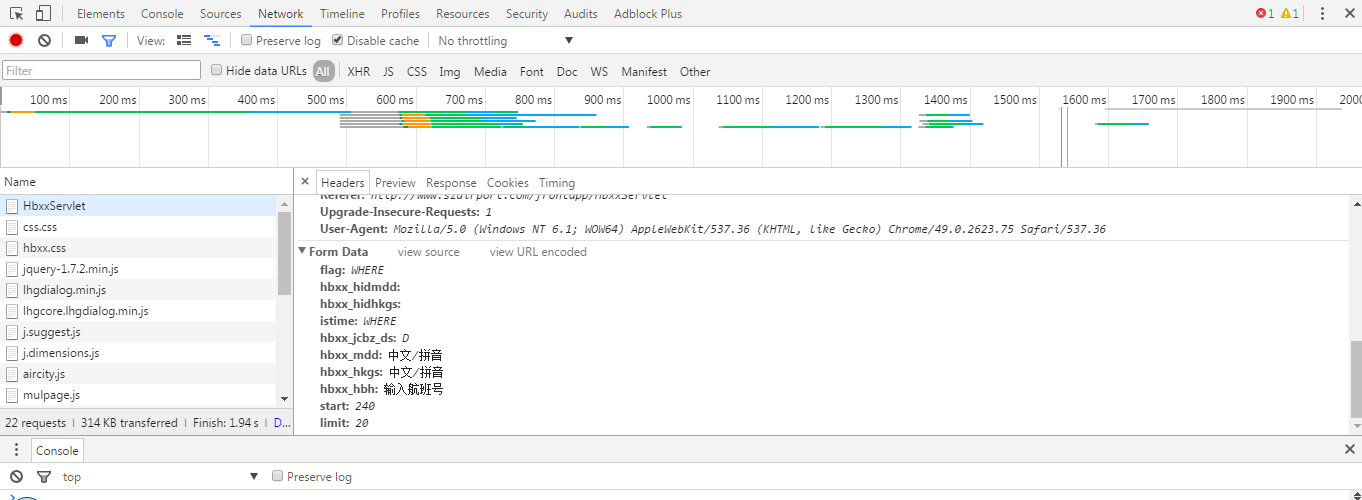
怎么抓取一个无论怎么跳转其url都不变的网页?通过Requests和BeautifulSoup能实现吗?
http://www.szairport.com/frontapp/HbxxServlet?iscookie=C
另外其下一页的跳转指令是js写的,我该怎么通过这条指令跳转下一页,命令如下:
[<a href="javascript:void(0);" onclick="page.moveNext()">下一页</a>]
另附上我修改的代码;
import requests
import re
import BeautifulSoup
import json
a={"start":150,"limit":20}
r=requests.post("http://www.szairport.com/frontapp/HbxxServlet",data=json.dumps(a))
soup=BeautifulSoup.BeautifulSoup(r.text)
print soup