各位大神,小弟我最近爬取闲鱼商品的时候出现个问题:
这个是网页源码截图,我想爬取里面这个赞数: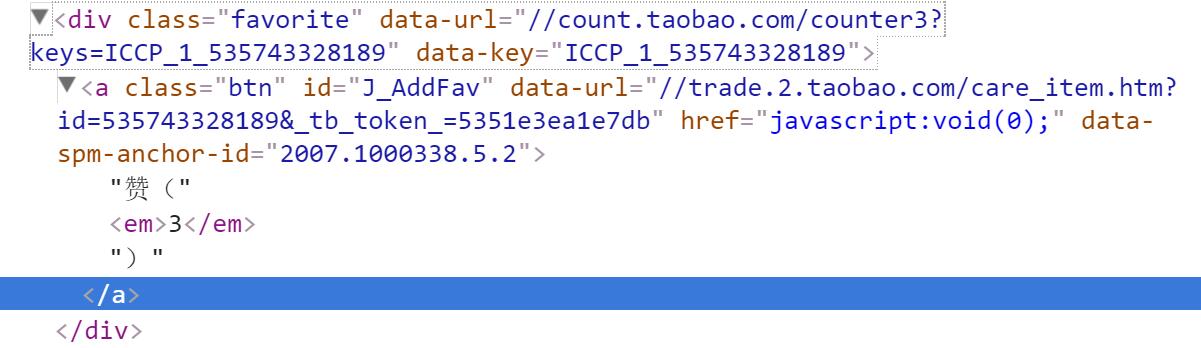
网页链接:https://2.taobao.com/item.htm?id=538626368021
下面是我的源码:
#! /usr/bin/env python
#coding=utf-8
import urllib
from bs4 import BeautifulSoup
import re
from lxml import etree
"""
https://s.2.taobao.com/list/list.htm?\
spm=2007.1000337.0.0.WOjjAq&st_trust=1&page=3&q=%C0%D6%B8%DF&ist=0
"""
def get_html(page=1, q="lego"):
"""获取商品列表页源代码,返回源代码content"""
params = {
"spm":"2007.1000337.0.0.WOjjAq",
"st_trust":"1",
"page":page,
"q":q,
"ist":"0"
}
info = urllib.urlencode(params)
url = "https://s.2.taobao.com/list/list.htm?" + info
html = urllib.urlopen(url)
content = html.read()
html.close()
return content
def get_url(content):
"""从商品列表页源代码中获取商品页url,返回url的列表"""
soup = BeautifulSoup(content, "lxml")
div_box = soup.find_all('div', class_='item-info')
url_list = []
for div in div_box:
url=div.find('h4', class_='item-title').a['href']
url_c = "https:" + url
url_list.append(url_c)
return url_list
def get_product(url):
html = urllib.urlopen(url)
content = html.read()
html.close()
content1 = content.decode('gbk').encode('utf-8')
rempat = re.compile('&')
content1 = re.sub(rempat,'&',content1)
root = etree.fromstring(content1)
zan = root.xpath('.//div[@id="J_AddFav"]/em/text()]')
return zan
if __name__ == '__main__':
content = get_html(1,"lego")
url_list = get_url(content)
url1 = url_list[1]
print url1
print get_product(url1)
问题出现在这里:
root = etree.fromstring(content1)
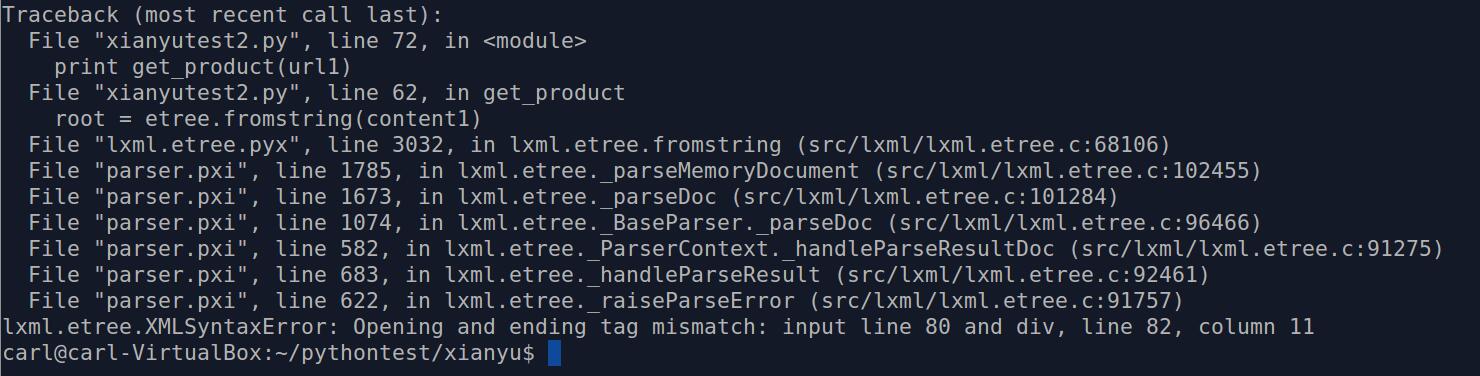
除了将&替换成&外没有对网页源码进行改动,不知为何源码会报错……
谢谢各位大神了,我是技术渣(我是学化学的……最近工作需要,拿闲鱼来练手,结果卡在这里一天了)






