python小白一枚,刚开始学爬虫,遇到一个动态网页爬取问题,请教各位大神。
需要爬取http://view.news.qq.com/original/intouchtoday/n4083.html
这篇新闻的评论内容,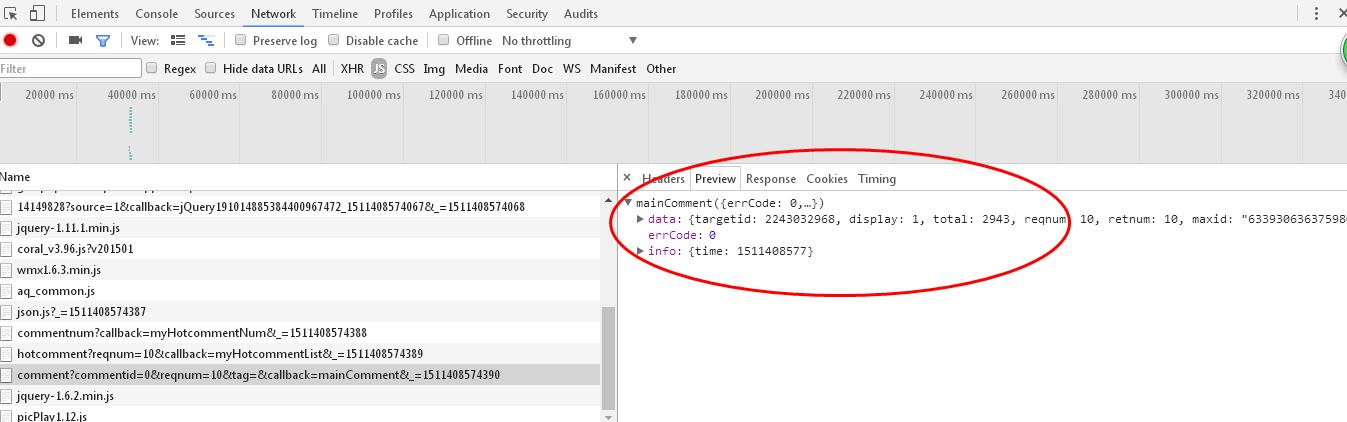
但是在找到了目标request url:
http://coral.qq.com/article/2243032968/comment?commentid=0&reqnum=10&tag=&ca,llback=mainComment&_=1511408574390
,不知道怎么提取里面的评论内容,且里面的内容类似于\u***这样的乱码
python爬虫爬取腾讯新闻评论

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新
 oyljerry 2017-11-23 06:09关注
oyljerry 2017-11-23 06:09关注需要先把内容的mainComment()去掉,它里面是一个json,然后就可以处理,\u是表示unicode的字符。
In [24]: sess = requests.Session() In [24]: sess.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Geck ...: o) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}) In [24]: res = sess.get("http://coral.qq.com/article/2243032968/comment?commentid=0&reqnum=10&tag=&callback=mainCommen ...: t&_=1511408574390") g = re.match("mainComment\\((.+)\\)", res.text) In [24]: out = json.loads(g.group(1)) In [23]: print(out["data"]["commentid"][0]["content"]) 方便面可以吃不放调料,自己煮,自己搭配本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2017-11-23 05:47回答 3 已采纳 需要先把内容的mainComment()去掉,它里面是一个json,然后就可以处理,\u是表示unicode的字符。 ``` In [24]: sess = requests.Session(
- 2022-10-18 21:52回答 1 已采纳 图片是从cdn上过来的,做了防盗链。在headers中添加Refer,指向该网站就行了。 import re import requests import os if not os.path.ex
- 2021-11-11 11:15回答 1 已采纳 先确定需要爬取的网站,然后分析网站的数据来源,是后端生成数据还是ajax生成数据,确定数据来源方式就根据HTTP请求编写代码,这个涉及一些请求参数的加密、转换等等处理,然后清洗数据和数据入库
- 2020-11-20 20:54weixin_39926040的博客 腾讯新闻的科技板块,至于为什么爬这个板块?我们要做新时代的科技少年???? ???? ???? 。闲话少叙,快上车。一、分析网页代码打开网页并进入调试模式,可以看的我们要爬取的内容都在这个 中。qqxw_01.png打开看看,...
- 2021-02-17 18:23回答 3 已采纳 在header参数中添加referer默认值,应该是直接访问触发反爬了
- 2021-05-22 21:34回答 1 已采纳 这里我们以爬取淘宝评论为例子讲解一下如何去做到的。 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析js
- 2021-11-27 22:00回答 2 已采纳 你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。requests只能获取网页的静态源代码,动态更新的内容取不到。对于动态更新的内容要用selenium 来爬取。 或者是通
- 2020-11-20 20:54weixin_39573981的博客 最近学了一段时间的Python,想写个爬虫,去网上找了找,然后参考了一下自己写了一个爬取给定页面的爬虫。Python的第三方库特别强大,提供了两个比较强大的库,一个requests, 另外一个BeautifulSoup,这两个库目前...
- 2022-08-17 17:07回答 3 已采纳 因为元素里的你要的内容是通过 ajax 请求动态加载的,可以浏览器抓包去看下,你想要的这条数据到底是哪个请求返回的,找到真正的请求,然后模拟发送就行了
- 2022-06-06 20:12回答 4 已采纳 你题目的解答代码如下: #coding=gbk import requests from io import BytesIO from PIL import Image from selenium
- 2022-03-11 17:52回答 2 已采纳 re模块,正则表达式,split切分
- 2021-04-09 22:29变强的猴子的博客 爬取腾讯新闻首页的新闻内容 最近学习了爬虫,爬了一些内容,分享一下,方便大家。 import urllib.request import urllib.error import re,ssl #异常处理 try: #针对https ,需要单独处理 #import ssl #ssl._...
- 2021-10-21 15:16回答 1 已采纳 该页面信息通过用户选择选项,js动态渲染加载数据的,比如在选项框中输入name,在XHR中就可以看到name的动态加载链接,对其进行请求可获取相关信息的json数据信息。
- 2020-08-23 07:32前端技术的博客 python爬虫爬取腾讯新闻 话不多说,直接上代码! import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() #r.encoding = 'utf-...
- 2023-09-18 13:26BUG再也不见的博客 对爬取的数据进行可视化
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 深度学习根据CNN网络模型,搭建BP模型并训练MNIST数据集
- ¥15 lammps拉伸应力应变曲线分析
- ¥15 C++ 头文件/宏冲突问题解决
- ¥15 用comsol模拟大气湍流通过底部加热(温度不同)的腔体
- ¥50 安卓adb backup备份子用户应用数据失败
- ¥20 有人能用聚类分析帮我分析一下文本内容嘛
- ¥15 请问Lammps做复合材料拉伸模拟,应力应变曲线问题
- ¥30 python代码,帮调试,帮帮忙吧
- ¥15 #MATLAB仿真#车辆换道路径规划
- ¥15 java 操作 elasticsearch 8.1 实现 索引的重建