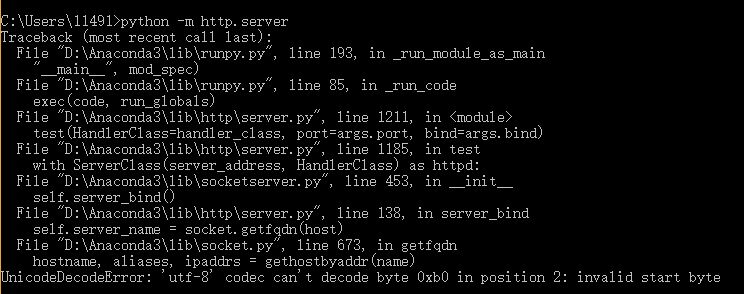

python启动http服务器出现unicodeDecodeError怎么解决

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


6条回答 默认 最新
 小码蚁啊 2018-01-24 07:33关注
小码蚁啊 2018-01-24 07:33关注一、编码的种种问题
背景: 使用linux开发环境,scureCRT客户端;想使用utf-8编码
1. 程序文件编码
就是你的程序文本文件保存时选取的编码,通过 file -i test_encoding.py 来查看如果不是UTF-8,假设是GBK,可以使用命令 iconv -f GBK -t utf-8 test_encode.py > tmp; mv tmp test_encode.py
2. 系统环境编码
对系统环境编码的设置,locale命令来查看如果不是可以使用命令 export LANG="zh_CN.utf-8"; export LC_CTYPE="zh_CN.utf-8" 来设置本次会话的编码;如果想一劳永逸,那还是打开 ~/.bashrc 把那两条命令射进去,然后 soure ~/.bashrc 一下。
3. scureCRT终端编码
选项=> 会话选项 => 终端 => 仿真 ,按照此路径在scureCRT客户端中展开,在右侧终端(T)的列表中选择linux
选项=> 会话选项 => 终端 => 外观,按照此路径找到内容,在右侧字符编码(H)的列表中选择UTF-8只有这三种编码都保持一致了,才基本可以保证中文编码不会乱
4. python 程序中的编码
按照1-3设置好以后,在test_encode.py中来一段python编码
import syslvchabiao="绿茶婊"
print lvchabiao
print type(lvchabiao)
print repr(lvchabiao)
执行: pythyon test_encode.py
报了一个大bug,晴空霹雳: SyntaxError: Non-ASCII character '\xe7' in file test_encode.py on line 4, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
看一下提示,错误出在第2行,也就是有中文的那行,这是因为python 解释器默认按照ascii码来解释,我们需要在python
程序的第一条语句处(该语句之前不能有任何语句),加上#-*-coding=utf-8-*- , 它告诉python解释器,该文件的内容按照utf-8编码来解释
#-*-coding=utf-8-*-
import sys
lvchabiao="绿茶婊"print lvchabiao
print type(lvchabiao)
print len(lvchabiao)print repr(lvchabiao)
二、python程序中的编码以及python程序与文件的编码交互
执行上面的程序,得到上图的结果;其中变量的类型为str, 长度为9,结合utf-8编码表示中文的时候是用3个字节,那么“绿茶婊”这个值就占用了9个字节,因此我们知道str类型存储的是字节序列。接下来让我们看看编码转换
1. 编码转换
再累计一段代码:
#utf-8 转 unicodeu = lvchabiao.decode('utf-8')
print u
print type(u)
print len(u)
print repr(u)
执行一下,会看到新增代码输出如下:
我们看到变量值的长度输出为3,即字符的个数,每个字符用2个字节编码(4个16进制的数值)
2. 编码与输出
我们执行python test_encode.py 输出到标准输出,没有问题;然后,执行python test_encode.py > tmp 却报错了,如下:错误显示在执行 " print u " 这个语句的时候无法按照ascii码来编码u这个变量(unicode编码),原因在于我们把结果输出到文件中的时候是按照字节流的方式,而unicode不是字节流的方式,我们需要把unicode编码编码为字节流格式的编码;python默认采用ascii编码,当用ascii编码去编码汉字的时候,无法表达这就出错了。因此,当我们要把unicode输出到文件之间,需要做编码转换,即将unicode编码编码为文件编码,程序修改为
print u.encode("utf-8")unicode字面变量转为unicode对象
在python程序中,python2.x 中,我们可以通过在字符串前面显示的加上一个u,来说明这个字符串是一个unicode编码的值;然而,当我们获得一份文件,文件中的内容为unicode编码的字面变量的时候,我们如何把这些字符串转成unicode变量呢?
例如:
u_value=u"\u7eff\u8336\u5a4a"
print u_value
str_value = "\u7eff\u8336\u5a4a"#从文件获得
print str_value.decode("raw_unicode_escape")设计json解析的时候,如何处理编码
编码在数据格式转换中不是对称的
python数据 转 json的规则: str, unicode => string
json数据 转python的规则:string => unicode
所以,当我们用json 的load函数解析出json数据,往文件中存储之前,需要用 str_data.encode("target_coding") 将数据转成想要的字符编码.
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2018-01-20 13:26回答 6 已采纳 一、编码的种种问题 背景: 使用linux开发环境,scureCRT客户端;想使用utf-8编码 1. 程序文件编码 就是你的程序文本文件保存时选取的编码,通过 file -i
- 2017-10-31 08:50回答 2 已采纳 编码问题, 文件前面加上这个前缀# -*- coding: utf-8 -*-
- 2022-09-26 08:52回答 2 已采纳 编码错误,在pycharm的右下角有相关的选项
- 2020-12-05 21:47weixin_39528697的博客 我在使用Python 3的服务器上运行了Django 1.8应用程序,在记录和打印带有特殊字符的字符串时,我得到了UnicodeDecodeError.>:python –version???python 3.4.3例如,如果我尝试在shell中运行一个愚蠢的方法:def ...
- 2022-08-05 17:25回答 1 已采纳 把你的-r去掉
- 2022-02-12 11:52回答 4 已采纳 stopword = [line.strip() for line in open(filepath, 'r').readlines()] 这一行的open()中加 encoding='utf-8'
- 2021-07-18 19:12回答 2 已采纳 这种错误可能是编码的问题!可是使用chardet检测编码。或者尝试各种编码: #PYTHON encodings = ['utf-8', 'windows-1250', 'windows-1252']
- 2020-11-29 16:48weixin_39725118的博客 Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化。编码是 unicode -> str,相反的,解码就是 str -> unicode。剩下的问题就是确定何时需要进行编码或者解码了.关于文件开头的"编码指示",也就是...
- 2022-06-10 16:07回答 1 已采纳 cahrdet有置信度的,换句话说,它也不是百分百自信检查出来的一定正确
- 2022-07-25 14:14回答 4 已采纳 编码不正确1.先打开txt,另存为,把编码格式改为utf82.open方法后面加参数,encoding='utf8'编码一致才能读出来
- 2022-09-10 14:10回答 2 已采纳 f=open(r'D:\政府工作报告.txt')改成f = open(r'D:\政府工作报告.txt', 'r', encoding='utf-8')试试?
- 2021-01-14 13:38weixin_39637924的博客 在我刚刚意识到在服务器上,python版本是2.7,它不允许我使用csv reader中的参数encoding来读取文件。在{否则我不能随时从cd1>中删除其余的数据集。我试着把网站上的所有问题都解决了,但什么也没解决。在我只想...
- 2023-04-22 11:47回答 3 已采纳 你确认文件编码是utf-8-sig吗? UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd4 in position 1: invalid
- 2021-12-24 17:26开开136的博客 /usr/bin/env python3 import datetime import email import html import http.server import io import mimetypes import os import posixpath import re import shutil import sys import urllib.error import ...
- 2021-07-16 10:37HooTJ的博客 1、使用Python3 内部提供的http.server python -m http.server(默认端口8000)。 默认情况下它会以当前运行目录为根目录,建立HTTP服务。如果当前目录存在index.html或者index.htm文件,那么默认会读取该文件...
- 2022-09-26 21:18ze言的博客 该服务器主要实现从客户端拷贝文件(.c)到指定目录,再把这个文件发送给服务器,并让服务器执行脚本,执行脚本需要用到这个.c文件进行编译,编译完告诉客户端,并且把编译生成的多个文件夹(含文件)发送给客户端...
- 2022-12-01 23:07ljhhh7890的博客 一个简单的python文件上传下载web服务器。
- 2022-12-20 12:43kevin丶小凯的博客 Python在进行编码方式之间的转换时,会将 unicode 作为“中间编码”,但 unicode 最大只有 128 那么长,所以这里当尝试将 ascii 编码字符串转换成"中间编码" unicode 时由于超出了其范围,就报出了如上错误。
- 2021-10-29 13:58将来怎么办的博客 这个问题真是搞得我头疼,后来看到一个文章 ...通过DBUG解决,分析出来是电脑名称的原因,注意是电脑名称,不是用户名称 我的是windows11所以直接在这里改就行 windows10可以看原文,哈哈,点我 ...
- 2020-12-09 18:15justride的博客 云服务器安装python3前言购买完云服务器之后,因为云服务器操作系统CentOS7自带的是python2,毕竟现在python3才是主流,很多之前编写的python文件运行有可能报错。安装python还麻烦的一点在于,因为CentOS7中,yum等...
- 没有解决我的问题, 去提问

