
代码如下:
package wordcount
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.rdd.RDD
object WordCount extends App {
val conf = new SparkConf()
//就是这里,为什必须要有它,它的具体作用到底是啥?
.set("spark.jars", "src/main/resources/sparkcore.jar,")
.set("spark.app.name", "WordCount")
.set("spark.master", "spark://master:7077")
.set("spark.driver.host", "win")
.set("spark.executor.memory", "512M")
.set("spark.eventLog.enabled", "true")
.set("spark.eventLog.dir", "hdfs://master:9000/spark/history")
val sc=new SparkContext(conf)
val lines:RDD[String]=sc.textFile("hdfs://master:9000/user/dsf/wordcount_input")
val words:RDD[String]=lines.flatMap(_.split(" "))
val wordAndOne:RDD[(String,Int)]=words.map((_,1))
val reduce:RDD[(String,Int)]=wordAndOne.reduceByKey(_+_)
val sorted:RDD[(String,Int)]=reduce.sortBy(_._2, ascending=false,numPartitions=1)
sorted.saveAsTextFile("hdfs://master:9000/user/dsf/wordcount_output")
println("\ntextFile: "+lines.collect().toBuffer)
println("flatMap: "+words.collect().toBuffer)
println("map: "+wordAndOne.collect().toBuffer)
println("reduceByKey: "+reduce.collect().toBuffer)
println("sortBy: "+sorted.collect().toBuffer)
sc.stop()
}
/**
在Linux终端运行此应用的命令行:
spark-submit \
--master spark://master:7077 \
--class wordcount.WordCount \
sparkcore.jar
*/
如果没有.set("spark.jars", "src/main/resources/sparkcore.jar,")这段代码,它会报这个异常:
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6, 192.168.1.15, executor 0): java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
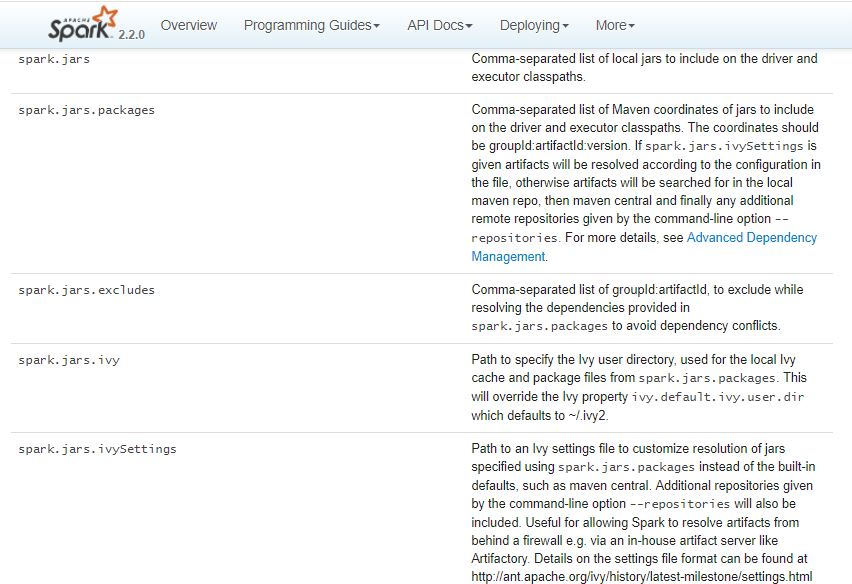
翻译过来是:
spark.jars: 以逗号分隔的本地jar列表,包含在驱动程序和执行程序类路径中。
按照官网的意思,是Driver和Excutor都应该有程序的jar包,可我不明白它的具体原理,哪位好心人给讲解一下,谢谢!







