import requests
from lxml import etree
import os
url='https://www.jdlingyu.com/38203.html'
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'
}
response=requests.get(url=url,headers=headers)
page= response.text
# print(html) //*[@id="primary-home"]/article/div[2]/p
tree=etree.HTML(page)
li_list=tree.xpath('//div[@id="primary-home"]/article/div[2]')
for li in li_list:
# name=li.xpath('./p/img/@loading="lazy"') 返回true
img_data = li.xpath('./p/img/@src')

到这一步要怎么保存图片到本地文件

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
 小P聊技术 2021-05-23 10:00关注
小P聊技术 2021-05-23 10:00关注给你个例子,这个是我抓取图片存储的
import requests from urllib.request import urlretrieve import re # encoding: utf-8 """ @version: 1.0 @author: AusKa_T @file: ex_umei @time: 2019/11/9 0009 10:42 """ def download_images(url, regex): response = requests.get(url) response.encoding = response.apparent_encoding html = response.text img_details = re.findall(regex, html) for i, src in enumerate(img_details): savename = r'downloads/{}_{}.png'.format(i + 1, src[1]) urlretrieve(src[0], savename) if __name__ == '__main__': download_images('http://www.umei.cc/weimeitupian/oumeitupian/', r'<img src="(.*?)" width="180" height="270" /><span>(.*?)</span>')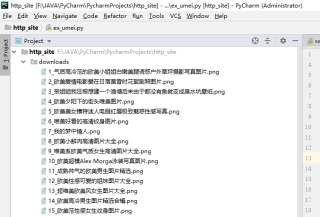 本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
- 2021-06-29 15:43回答 2 已采纳 你的temp只是一个字符串,应该是一个url,你还没发送请求,用requests发送一下请求
- 2021-07-13 10:36回答 4 已采纳 你写代码的时候,把自己要存放的路径加在save()里面就可以了
- 2022-04-07 11:17回答 3 已采纳 w改为a(追加),要不会将当前写入的内容覆盖文件内容 要么将open和close放到for循环外
- 2019-02-16 20:46努力努力再努力的博客 今天搜索电脑壁纸突发奇想就把所有壁纸怕取下来了 百度 壁纸 随便挑了一个点进去是zol电脑壁纸ZOL桌面壁纸 现在开始爬取 import requests ...def baocun(url):#此方法是将图片保存文件到本地 只需要传入图片...
- 2021-09-30 11:00回答 3 已采纳 你好,根据你的提的问题,我做了如下demo filename = '微信截图_20210930132446.png' with open(filename ,'rb') as f: with
- 2021-09-06 21:01回答 1 已采纳 matlab是高度优化的软件,你的A在matlab里面甚至可以储存为1k以下,要是它只用压缩存储的话,那么存储的东西就是(1)矩阵大小:3个整型数[62, 500, 200];(2)矩阵值:1个双精度
- 2022-04-26 10:15回答 8 已采纳 ##这样呢with open('/Users/chendingyu/Desktop/20220411/510880.dat','rb') as fo: #读入 data=fo.read()
- 2021-06-24 17:37早上起来要吃饭的博客 爬虫请求解析后的数据,需要保存下来,才能进行下一步的处理,一般保存数据的方式有如下几种: 文件:txt、csv、excel、json等,保存数据量小。 关系型数据库:mysql、oracle等,保存数据量大。 非关系型数据库:...
- 2021-05-23 19:41回答 2 已采纳 #按月输出本年日历,星期日在前,并将上述日历输出至文件 。 import calendar#导入日历模块 print(calendar.setfirstweekday(6))#将星期日放在前 s
- 2021-07-09 09:47回答 2 已采纳 用datetime函数转换一下日期,使用pandas提取出指定日期的数据,to_csv保存为另一个csv文件即可。转换语句可以用data['date'] = data['date'].apply(la
- 2018-12-27 20:55回答 2 已采纳 没有save这个方法
- 2021-03-17 14:52蟹蟹碎冰冰的博客 本文包含以下内容:何为云桥模式如何开始使用云桥安装注意事项使用云桥模式可能会遇到的问题何为云桥模式:当您在Mac电脑上安装了坚果云客户端之后,坚果云中的所有同步文件夹无需全部同步到本地电脑上。坚果云会把...
- 2021-08-15 09:33回答 1 已采纳 试试 data.to_csv(r'E:/PP/boston.csv',index=False)
- 2020-11-30 08:55weixin_39822923的博客 python-尝试将Excel文件保存为图片并加上水印场景:并不是将 excel 的 chart 生成图片,而是将整个表格内容生成图片。1. 准备工作目前搜索不到已有的方法,只能自己尝试写一个,想法有两个:通过 Python 的图片处理...
- 2022-05-25 11:37一起躺躺躺的博客 我想要用的数据存在一个.dat文件中,但是这个文件中除了我想要的数据还有很多其他杂乱的内容,所以需要有一个寻找我想要内容的过程,见下图,我想要的是图中标亮部分及以后的数据;我需要将这些数据按顺序读出,并将...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 我的R语言提示去除连锁不平衡时clump_data报错,图片以下所示,卡了好几天了,苦恼不知道如何解决,有人帮我看看怎么解决吗?
- ¥15 在获取boss直聘的聊天的时候只能获取到前40条聊天数据
- ¥20 关于URL获取的参数,无法执行二选一查询
- ¥15 液位控制,当液位超过高限时常开触点59闭合,直到液位低于低限时,断开
- ¥15 marlin编译错误,如何解决?
- ¥15 有偿四位数,节约算法和扫描算法
- ¥15 VUE项目怎么运行,系统打不开
- ¥50 pointpillars等目标检测算法怎么融合注意力机制
- ¥20 Vs code Mac系统 PHP Debug调试环境配置
- ¥60 大一项目课,微信小程序