如:深圳龙岗区中海信创新产业城15栋(距离地铁10号线凉帽山地铁站D出口30米) 这个字符串 跟表里的所有地址信息做相似度计算 输出对应匹配度最高的字符串跟数值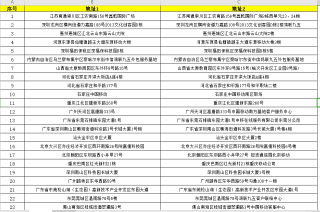

将获取到的地址信息跟Excle表中的所有地址信息做相似度计算

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新
 Jason Ho 2021-07-27 11:47关注
Jason Ho 2021-07-27 11:47关注# -*- coding: utf-8 -*- import jieba import numpy as np import re def get_word_vector(s1,s2): """ :param s1: 句子1 :param s2: 句子2 :return: 返回句子的余弦相似度 """ # 分词 cut1 = jieba.cut(s1) cut2 = jieba.cut(s2) list_word1 = (','.join(cut1)).split(',') list_word2 = (','.join(cut2)).split(',') # 列出所有的词,取并集 key_word = list(set(list_word1 + list_word2)) # 给定形状和类型的用0填充的矩阵存储向量 word_vector1 = np.zeros(len(key_word)) word_vector2 = np.zeros(len(key_word)) # 计算词频 # 依次确定向量的每个位置的值 for i in range(len(key_word)): # 遍历key_word中每个词在句子中的出现次数 for j in range(len(list_word1)): if key_word[i] == list_word1[j]: word_vector1[i] += 1 for k in range(len(list_word2)): if key_word[i] == list_word2[k]: word_vector2[i] += 1 # 输出向量 print(word_vector1) print(word_vector2) return word_vector1, word_vector2 def cos_dist(vec1,vec2): """ :param vec1: 向量1 :param vec2: 向量2 :return: 返回两个向量的余弦相似度 """ dist1=float(np.dot(vec1,vec2)/(np.linalg.norm(vec1)*np.linalg.norm(vec2))) return dist1 def filter_html(html): """ :param html: html :return: 返回去掉html的纯净文本 """ dr = re.compile(r'<[^>]+>',re.S) dd = dr.sub('',html).strip() return dd if __name__ == '__main__': s1="很高兴见到你" s2="我也很高兴见到你" vec1,vec2=get_word_vector(s1,s2) dist1=cos_dist(vec1,vec2) print(dist1)本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
问题事件
 系统已结题
8月4日
系统已结题
8月4日 已采纳回答
7月27日
已采纳回答
7月27日-
创建了问题
7月27日
悬赏问题
- ¥15 三因素重复测量数据R语句编写,不存在交互作用
- ¥15 微信会员卡等级和折扣规则
- ¥15 微信公众平台自制会员卡可以通过收款码收款码收款进行自动积分吗
- ¥15 随身WiFi网络灯亮但是没有网络,如何解决?
- ¥15 gdf格式的脑电数据如何处理matlab
- ¥20 重新写的代码替换了之后运行hbuliderx就这样了
- ¥100 监控抖音用户作品更新可以微信公众号提醒
- ¥15 UE5 如何可以不渲染HDRIBackdrop背景
- ¥70 2048小游戏毕设项目
- ¥20 mysql架构,按照姓名分表