
最近在学爬虫,准备拿学校微信公众号试试手,但是发现token取不出来。。。
用Print大法,发现token总是为0 。。。,这是什么情况。。。
部分代码如下
def get_content(query):
url = 'https://mp.weixin.qq.com'
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
print(response.url)
res = requests.get(response.url)
token = re.findall(r'token=(\d+)', res.text)
print(token)
这张图是我把res.text保存下来后看的,发现token里为空
但是我自己进平台主页看源码里,其实是有token的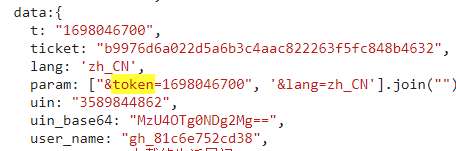
难道说我其实没有登陆进去吗?怎么看自己是不是已经登陆成功了呢。。。





