
我用hmmer进行多序列比对后生成结果文件后,现在需要将数据库中相对应的序列提取出来,目前已经提取出来了为result.txt,但是提取出的序列顺序与hmmer比对结果文件的顺序不相符,需要对其进行重排序,所以需要一个脚本来实现,希望大大们可以不吝赐教。我目前已经有这些序列的hmm比对ID文件ID.txt了。
简明一下就是:
我有一个ID.txt文件:
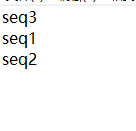
生成的result.txt文件是:

想要通过脚本生成的是:

顺序和ID文件的顺序一致。
上述说明只是简要说明,实际操作的时候序列数量比3个多得多,所以希望大大们能够写个n个数据量的脚本。
ID.txt和result.txt对应的序列数目是相等的。
感谢各位大大教导!







