
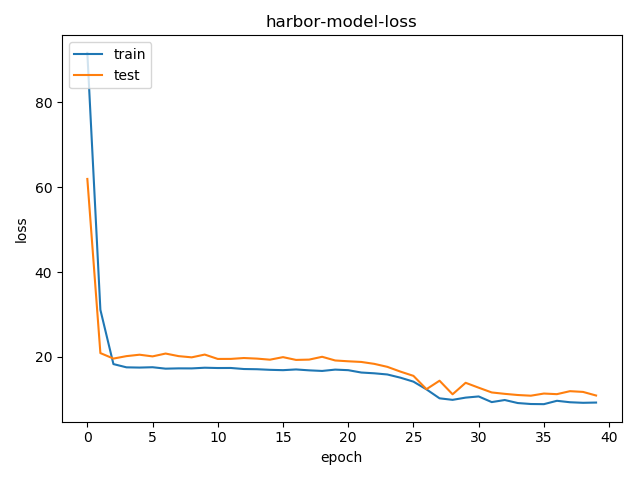
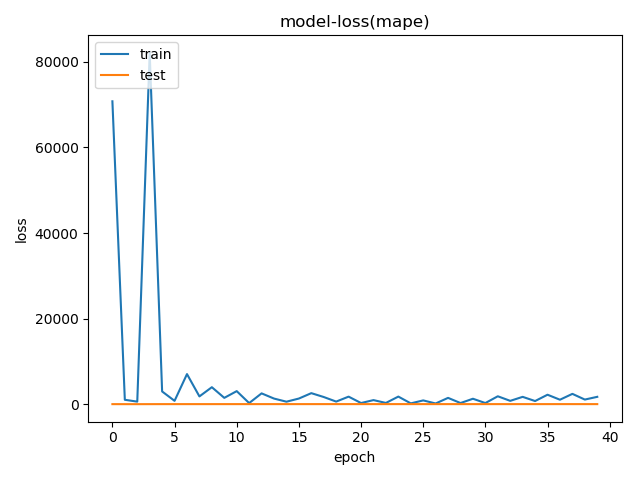
上图是1000个样本训练模型的损失函数(mape 平均绝对百分误差)结果,下图为样本数量增加到2000个,损失函数就看不懂了,每个epoch下降到80左右就上跳到一个较大的值,尤其是当mape在80多的时候accracy都为0。然后开始下降
附上模型代码
### model
taxi_id = Input(shape=(50, 1))
mask_1 = Masking(mask_value=0)(taxi_id)
embedding_1 = Embedding(15000, 14, mask_zero=True)(mask_1)
time_id = Input(shape=(50, 1))
mask_2 = Masking(mask_value=0)(time_id)
embedding_2 = Embedding(1440, 6, mask_zero=True)(mask_2)
busy = Input(shape=(50, 1))
mask_3 = Masking(mask_value=0)(busy)
embedding_3 = Embedding(2, 2, mask_zero=True)(mask_3)
concatenate_1 = Concatenate(axis=3)([embedding_1,embedding_2,embedding_3])
concatenate_1 = Lambda(dim_squeeze)(concatenate_1)
num_input = Input(shape=(50, 3))
mask_4 = Masking(mask_value=0, input_shape=())(num_input)
concatenate_2 = Concatenate(axis=2)([concatenate_1, mask_4])
blstm_1 = Bidirectional(LSTM(128, activation='tanh', return_sequences=True, dropout=0.2))(concatenate_2)
blstm_2 = Bidirectional(LSTM(256, activation='tanh', return_sequences=True, dropout=0.2))(blstm_1)
blstm_3 = Bidirectional(LSTM(128, activation='tanh', return_sequences=True, dropout=0.2))(blstm_2)
dense_1 = Dense(128)(blstm_3)
leaky_relu_1 = advanced_activations.LeakyReLU(alpha=0.3)(dense_1)
dense_2 = Dense(128)(leaky_relu_1)
leaky_relu_2 = advanced_activations.LeakyReLU(alpha=0.3)(dense_2)
dense_3 = Dense(128)(leaky_relu_2)
leaky_relu_3 = advanced_activations.LeakyReLU(alpha=0.3)(dense_3)
dense_4 = Dense(128)(leaky_relu_3)
leaky_relu_4 = advanced_activations.LeakyReLU(alpha=0.3)(dense_4)
add_1 = add([leaky_relu_1, leaky_relu_2, leaky_relu_3, leaky_relu_4])
dense_5 = Dense(1, activation='linear')(add_1)
dense_5 = Lambda(dim_squeeze)(dense_5)
dense_5 = Dense(units = 1, activation='linear')(dense_5)
model = Model([taxi_id, time_id, busy, num_input], dense_5)
求大佬过目指点迷津,这样的损失函数意味着哪里出了问题,先行谢过






