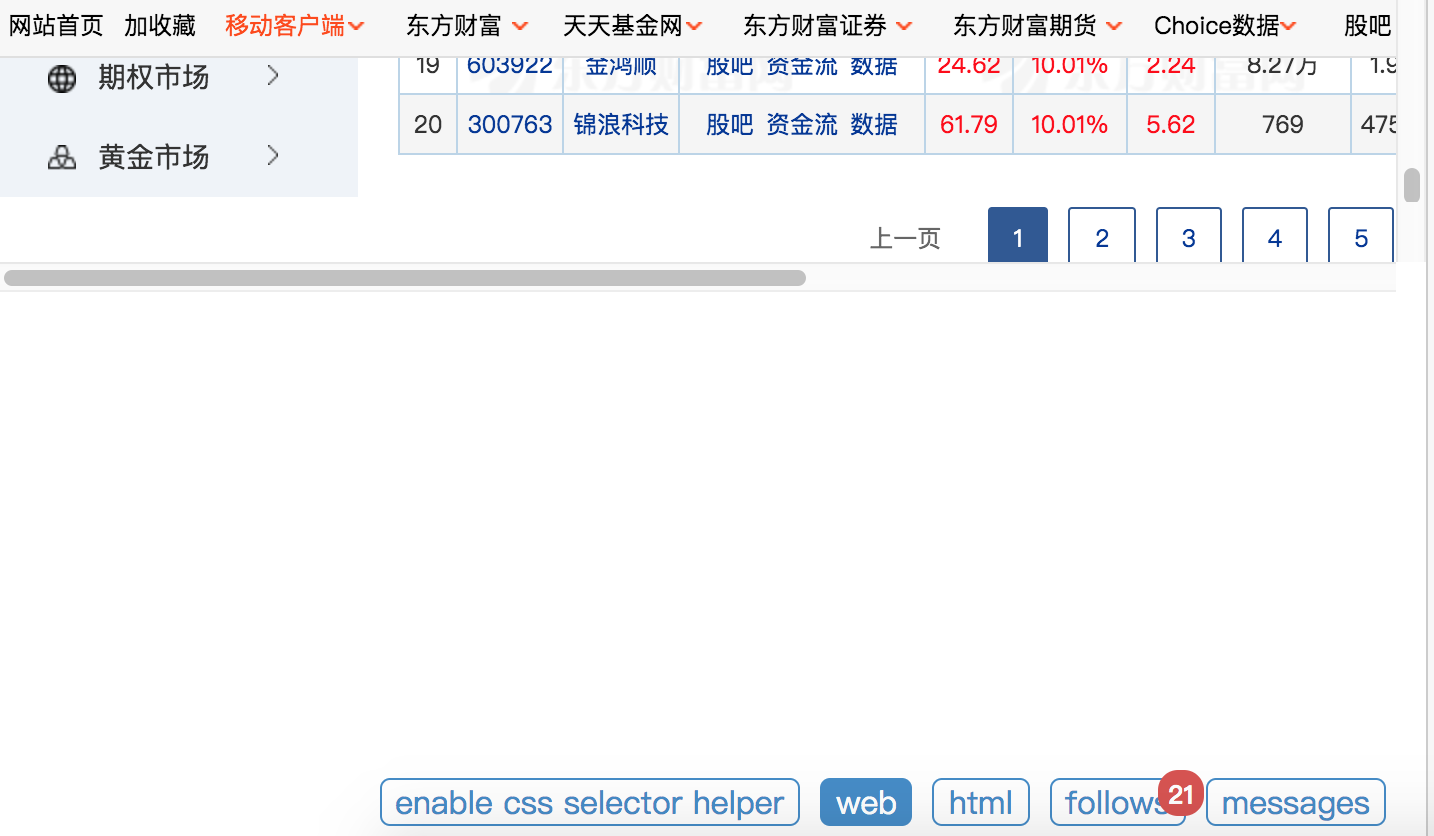
使用pyspidert爬取股票中的内容,在点击下一页后url链接并不改变,只改变了js渲染中的内容,所以无法使用网上的教程。
在使用pyspider内嵌JavaScript时,也只能爬取第一页,无法爬取之后的内容。
def index_page(self, response):
for each in response.doc('#main-table > tbody > tr > td.listview-col-Code > a').items():
self.crawl(each.attr.href, callback=self.list_page)
#翻页
self.crawl(response.url, callback=self.index_page, fetch_type='js',js_script='''function() {setTimeout("$('.next').click()", 5000);}''')
第一次爬取后,20支股票和自己页面链接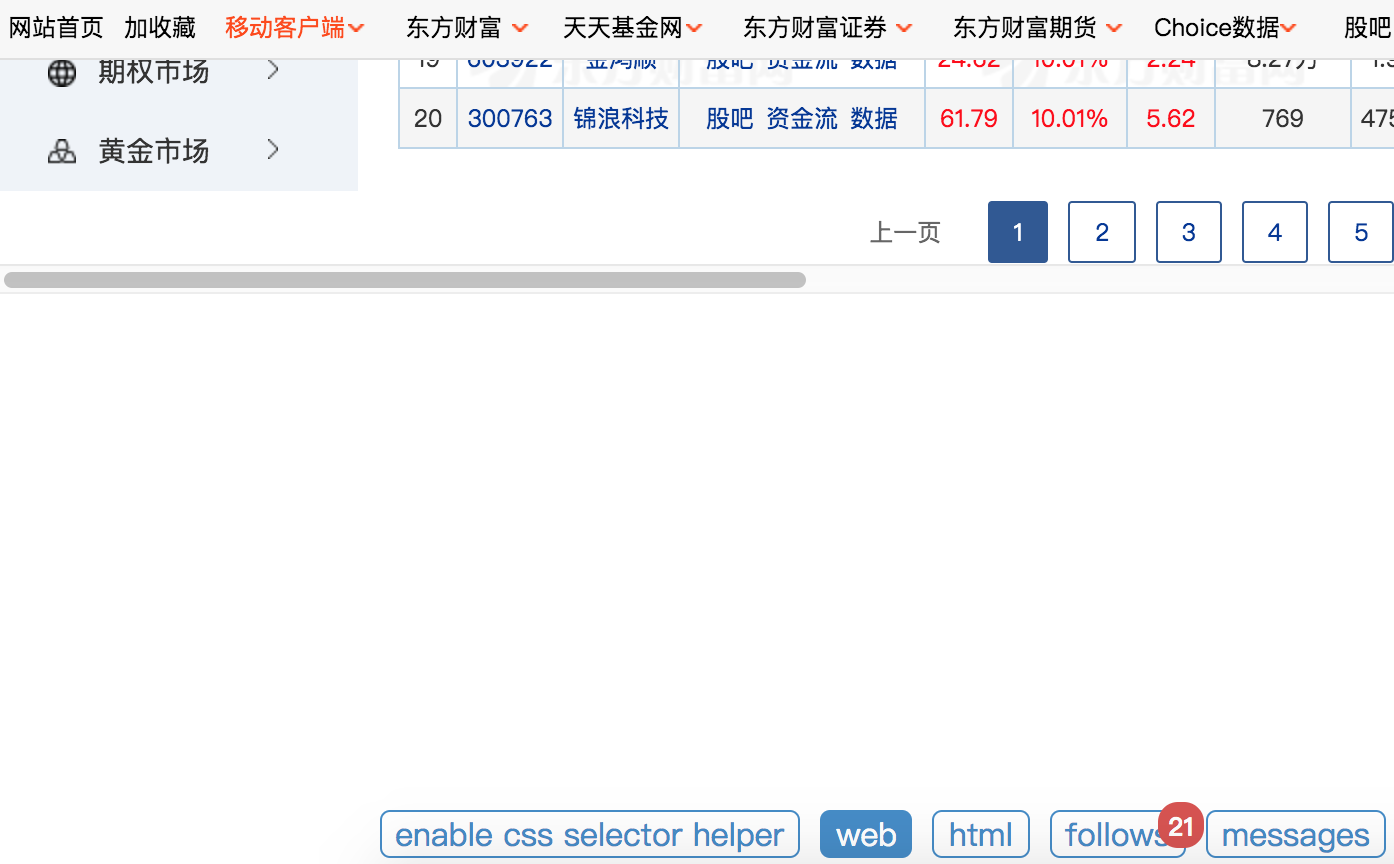
第二次爬取本链接,希望得到第二页内容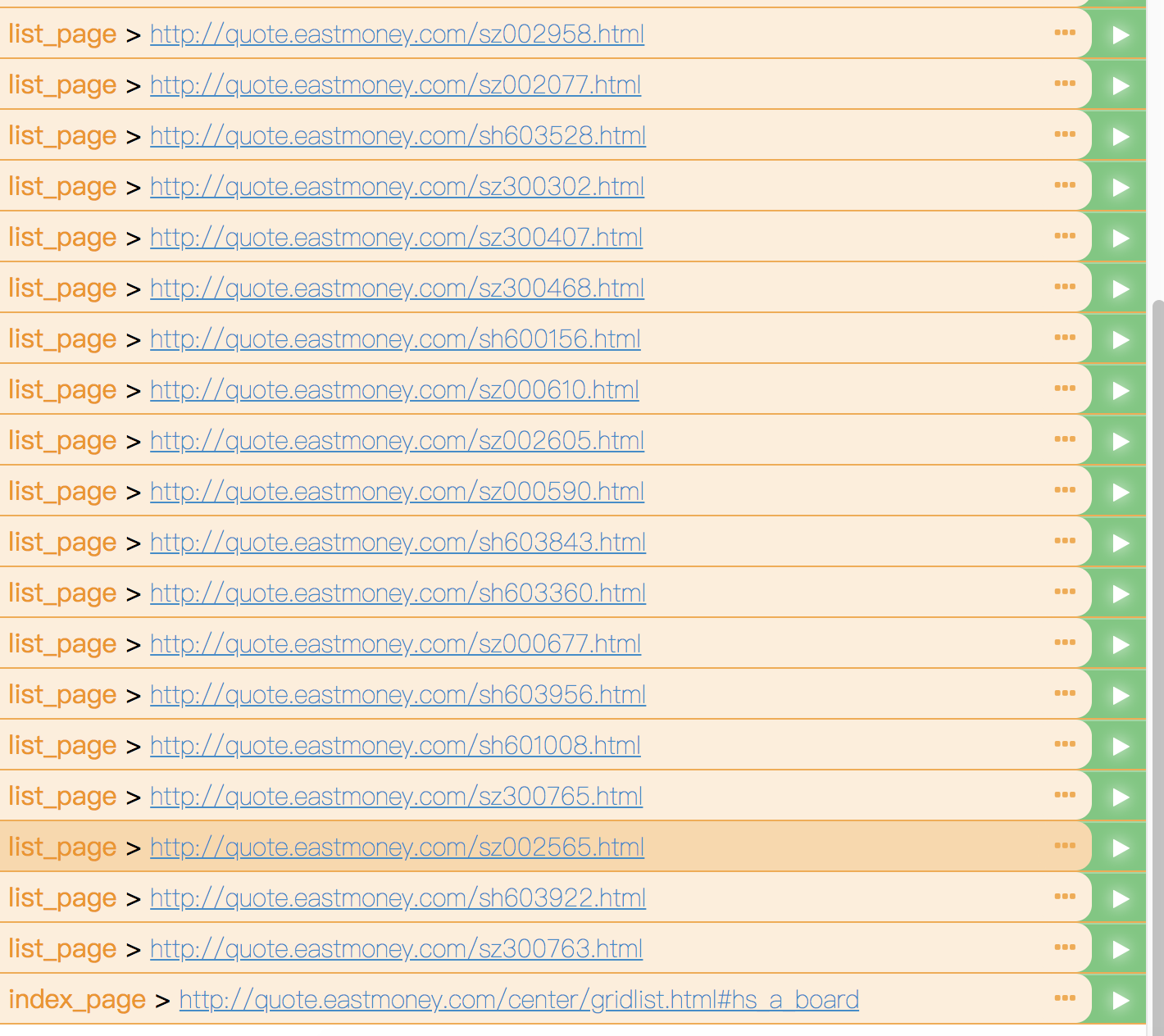
结果还是第一页,