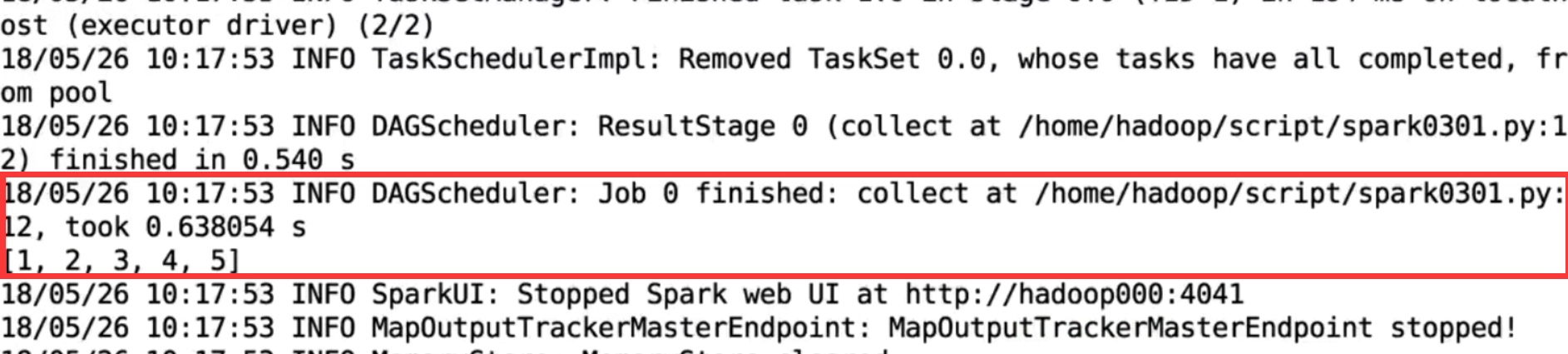
遇到的问题有两个
先上代码:
from pyspark import SparkConf, SparkContext
conf = SparkConf()\
#.setMaster("local[2]").setAppName("spark0301")
sc = SparkContext(conf=conf)
data = [1,2,3,4,5]
disData = sc.parallelize(data)
disData.collect()
sc.stop()
一.window环境下
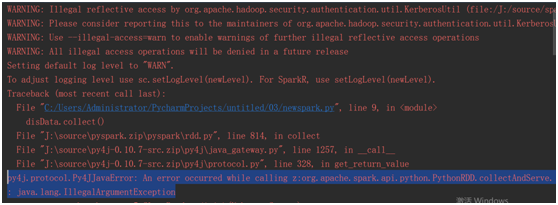
二.pyspark 单机模式下
./spark-submit --master local[2] --name spark0001 /root/datas/text1.py
我运行的结果
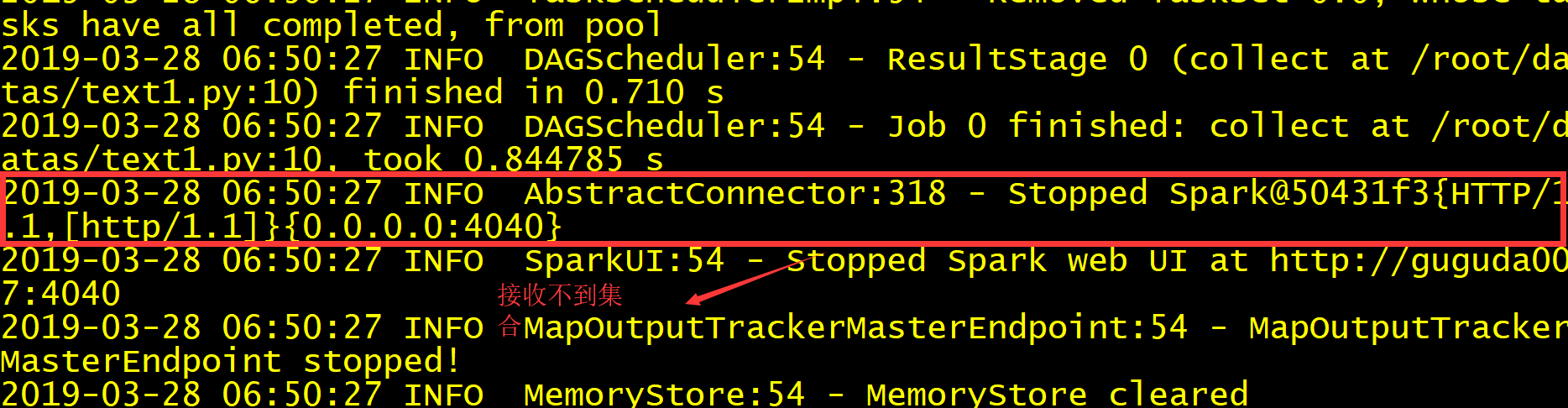
正常别人运行的结果