
问题截图: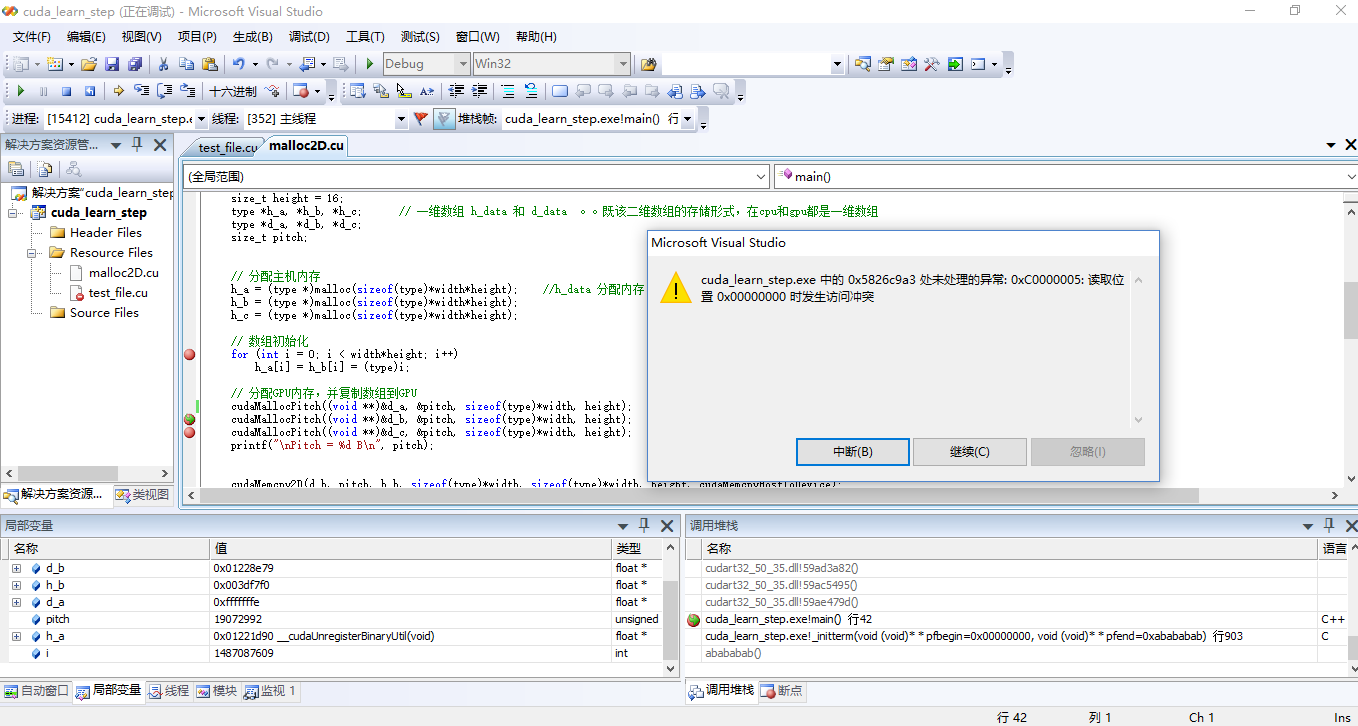
1、该异常经常发生,包括来自《cuda高性能编程 cuda实战》书中的代码,自己写的一些代码等。但是不是一定会发生。
2、调试时发现,异常产生的位置都是在主函数中,当调用了cudaMalloc函数分配内存后,接着调用第二个cuda函数时就会出现该异常,比如用cudaMalloc为第二个变量分配内存,或是用cudaMemcpy向GPU复制数据。
举个例子:
这段代码没有问题(只为一个数组分配了内存并在核函数中计算)
#include <stdio.h>
#include <malloc.h>
#include <cuda_runtime_api.h>
#include "device_launch_parameters.h"
#define type float
__global__ void myKernel(type* d_a, int height, int width, int pitch) //四个形参:数组名,高,行宽,行字节数
{
int tx = blockDim.x * blockIdx.x + threadIdx.x;
int ty = blockDim.y * blockIdx.y + threadIdx.y;
if( tx<width && ty<(height) )
d_a[ty*width+tx] *= 10;
}
int main()
{
// 定义参数:高、宽、数组
size_t width = 16;
size_t height = 10;
type *h_a;
type *d_a;
type *d_b;
size_t pitch;
// 分配主机内存
h_a = (type *)malloc(sizeof(type)*width*height); //h_data 分配内存:宽*高
// 数组初始化
for (int i = 0; i < width*height; i++)
h_a[i] = (type)i;
// 分配GPU内存,并复制数组到GPU
cudaMallocPitch((void **)&d_a, &pitch, sizeof(type)*width, height);
cudaMemcpy2D(d_a, pitch, h_a, sizeof(type)*width, sizeof(type)*width, height, cudaMemcpyHostToDevice); //
printf("\nPitch = %d B\n", pitch);
cudaMalloc((void **)&d_b, sizeof(type)*width);
//分配二维线程
dim3 threadsPerBlock(8,8);
dim3 blocksPerGrid((width+threadsPerBlock.x-1)/threadsPerBlock.x,(height+threadsPerBlock.y-1)/threadsPerBlock.y); // +threadsPerBlock.x-1
//核函数执行
myKernel <<< blocksPerGrid ,threadsPerBlock >>> (d_a, height, width, pitch); //参数:d_data,高度,行宽,行字节数
cudaDeviceSynchronize();
//复制数组回CPU
cudaMemcpy2D(h_a, sizeof(type)*width, d_a, pitch, sizeof(type)*width, height, cudaMemcpyDeviceToHost);
for (int i = width*(height - 10); i < width*height; i++)
{
printf("%10.2f", h_a[i]);
if ((i + 1) % width == 0)
printf("\n");
}
free(h_a);
cudaFree(d_a);
getchar();
return 0;
}
在这个基础上改了之后,变为为三个变量分配内存并在核函数中计算就发生问题了。
#include <stdio.h>
#include <malloc.h>
#include <cuda_runtime_api.h>
#include "device_launch_parameters.h"
#define type float
__global__ void myKernel(type* d_a, type* d_b, type* d_c, int height, int width, int pitch) //四个形参:数组名,高,行宽,行字节数
{
int tx = blockDim.x * blockIdx.x + threadIdx.x;
int ty = blockDim.y * blockIdx.y + threadIdx.y;
if( tx<width && ty<height )
d_c[ty*width+tx] = pow( d_b[ty*width+tx] - d_a[ty*width+tx] , 2 );
}
int main()
{
// 定义参数:高、宽、数组
size_t width = 160;
size_t height = 16;
type *h_a, *h_b, *h_c; // 一维数组 h_data 和 d_data 。。既该二维数组的存储形式,在cpu和gpu都是一维数组
type *d_a, *d_b, *d_c;
size_t pitch;
// 分配主机内存
h_a = (type *)malloc(sizeof(type)*width*height); //h_data 分配内存:宽*高
h_b = (type *)malloc(sizeof(type)*width*height);
h_c = (type *)malloc(sizeof(type)*width*height);
// 数组初始化
for (int i = 0; i < width*height; i++)
h_a[i] = h_b[i] = (type)i;
// 分配GPU内存,并复制数组到GPU
cudaMallocPitch((void **)&d_a, &pitch, sizeof(type)*width, height); //分配gpu内存:d_data 数组名地址,pitch地址,行字节数,高度
cudaMallocPitch((void **)&d_b, &pitch, sizeof(type)*width, height);
cudaMallocPitch((void **)&d_c, &pitch, sizeof(type)*width, height);
printf("\nPitch = %d B\n", pitch);
cudaMemcpy2D(d_b, pitch, h_b, sizeof(type)*width, sizeof(type)*width, height, cudaMemcpyHostToDevice);
cudaMemcpy2D(d_a, pitch, h_a, sizeof(type)*width, sizeof(type)*width, height, cudaMemcpyHostToDevice); //目标数组名,目标行字节数,原数组名,源行字节数,数组实际行字节数,高
//分配二维线程
dim3 threadsPerBlock(8,8);
dim3 blocksPerGrid((width+threadsPerBlock.x-1)/threadsPerBlock.x,(height+threadsPerBlock.y-1)/threadsPerBlock.y); // +threadsPerBlock.x-1
//核函数执行
myKernel <<< blocksPerGrid ,threadsPerBlock >>> (d_a, d_b, d_c, height, width, pitch); //参数:d_data,高度,行宽,行字节数
cudaDeviceSynchronize(); //一个同步函数。该方法将停止CPU端线程的执行,直到GPU端完成之前CUDA的任务,包括kernel函数、数据拷贝等。
//复制数组回CPU
cudaMemcpy2D(h_c, sizeof(type)*width, d_c, pitch, sizeof(type)*width, height, cudaMemcpyDeviceToHost);
for (int i = width*(height - 10); i < width*height; i++)
{
printf("%10.2f", h_c[i]);
if ((i + 1) % width == 0)
printf("\n");
}
free(h_a);
free(h_b);
free(h_c);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
getchar();
return 0;
}






