
通过lucene实现全文检索确实很高效,目前创建索引,检索都已经实现。
但问题是对检索结果的排序,之前都是采用lucene默认的排序。由于lucene默认的打分方式有很多种,最终综合排序。倒也可以满足大部分需求。但是现在客户提了一个要求,希望将分词后靠在一起的排最前面。
比如用户搜索“中国很大”,分词后为中国、很大;如果其中有一条数据包含中国很大,并且是靠在一起,哪怕只出现一次,也将它排在最前面。而其它数据即使出现中国或很大次数再次,只要没靠在一起,最排在后面,以靠在一起为最优先出现在前面。请问怎么实现?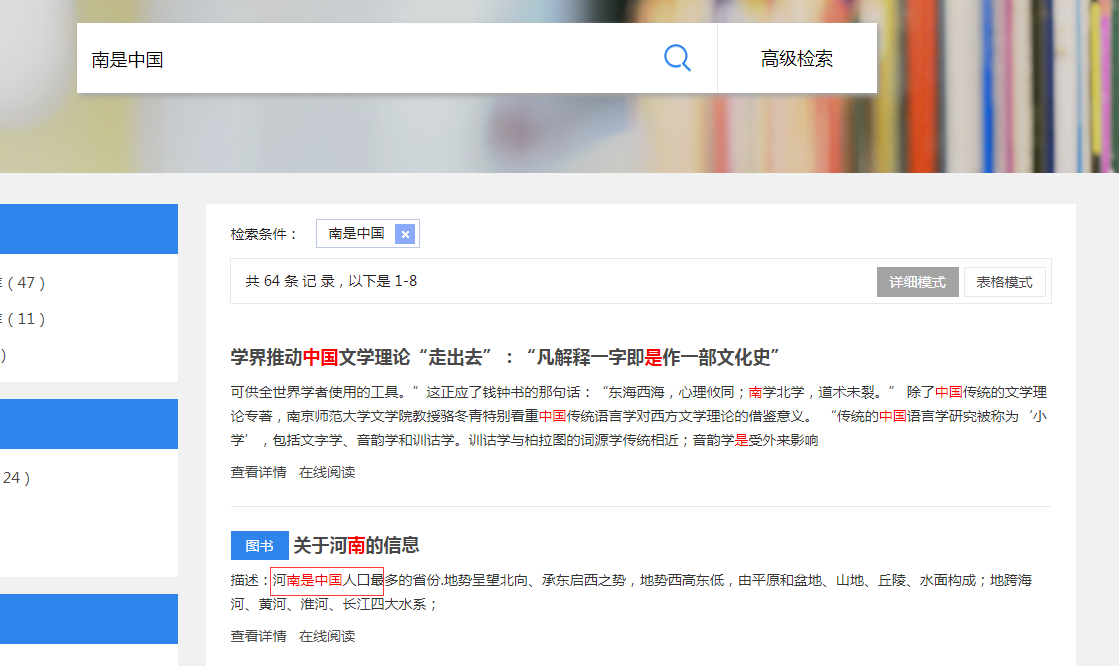
比如这个例子,用户检索“南是中国”,其中第二条的内容中有连续出现检索内容,而第一条虽然出现的词更多,确没有连续出现的,所以希望第二条这种优先排在最前面;请问这种排序应该如何实现??






