问题遇到的现象和发生背景
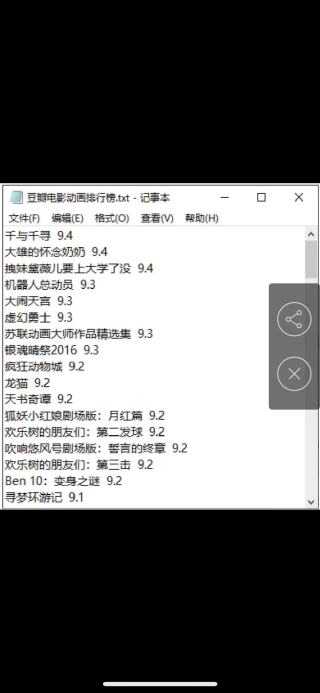
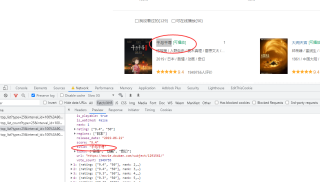
爬取豆瓣网动画片最高分,按照书上的代码敲出来后报错了,如图
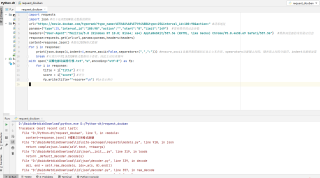
补充代码:
import requests
import json #用于处理JSON格式数据的模块
url="https://movie.douban.com/typerank?type_name=%E5%8A%A8%E7%94%BB&type=25&interval_id=100:90&action=" #请求地址
params={"type":25,"interval_id":"100:90","action":"","start":"0","limit":"149"} #需要携带的动态参数
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"} #模拟浏览器的身份验证信息
response=requests.get(url=url,params=params,headers=headers)
content=response.json() #提取JSON格式数据
for i in response:
print(json.dumps(i,indent=4,ensure_ascii=False,separators=(",",":"))) #ensure_ascii设置将数据编码后显示文本内容,spearators设置键之间的、键和值之间的分隔符,indent设置缩进量
break #只需打印第1条JSON格式数据用于查看,因此主动结束循环
with open("豆瓣电影动画排行榜.txt","w",encoding="utf-8") as fp:
for i in response:
title = i["title"] #片名
score = i["score"] #评分
fp.write(title+""+score+"\n") #\n表示换行
操作环境、软件版本等信息
环境不知道是什么环境,软件是PYCharm
尝试过的解决方法
百度说需要添加其他代码,因为是跨专业初学者,实在是不知道要加什么代码
我想要达到类似于这样的结果
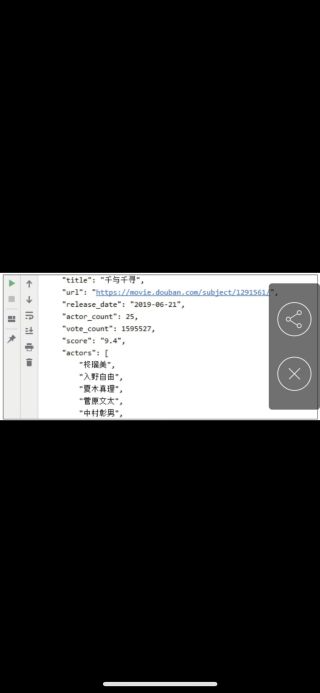
补充:最后导出在txt文件里了,所以应该出现类似于这样的效果