
手头有份数据,需要根据另一份标准指标(数据有含有几个指标,每个指标都各自的等级划分,示意图如下)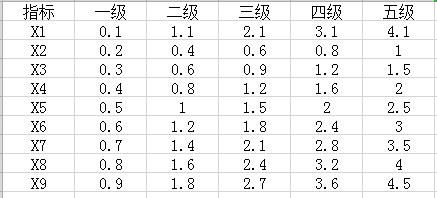
我需要将手头的数据,根据这个标准值,将对应的数值全部转换成对应的等级。自己写了份代码,但是运行速度太慢(1000个数据,运行了居然2-3分钟)。。
想请问下高手们,有什么办法改进没?
具体代码如下:
for zb in list(data_std['指标']):
for num in range(data.shape[0]):
if zb !='DISSOLVED_O2': #某指标比较特殊,数值越大越好。其余指标是数值越小越好。因此要单独设置
if (data[zb][num]) <= float(data_std[data_std['指标'] ==zb]['I']):
data['%s_wq'%zb][num] = 1
elif float(data_std[data_std['指标'] ==zb]['I']) < data[zb][num] <= float(data_std[data_std['指标'] ==zb]['II']):
data['%s_wq'%zb][num] = 2
elif float(data_std[data_std['指标'] ==zb]['II']) < data[zb][num] <= float(data_std[data_std['指标'] ==zb]['III']):
data['%s_wq'%zb][num] = 3
elif float(data_std[data_std['指标'] ==zb]['III']) < data[zb][num] <= float(data_std[data_std['指标'] ==zb]['IV']):
data['%s_wq'%zb][num] = 4
elif float(data_std[data_std['指标'] ==zb]['IV']) < data[zb][num] <= float(data_std[data_std['指标'] ==zb]['V']):
data['%s_wq'%zb][num] = 5
elif (data[zb][num]) > float(data_std[data_std['指标'] ==zb]['V']):
data['%s_wq'%zb][num] = 6
else:
data['%s_wq'%zb][num] = np.NaN
if zb =='DISSOLVED_O2':
if (data[zb][num]) >= float(data_std[data_std['指标'] ==zb]['I']):
data['%s_wq'%zb][num] = 1
elif float(data_std[data_std['指标'] ==zb]['I']) > data[zb][num] >= float(data_std[data_std['指标'] ==zb]['II']):
data['%s_wq'%zb][num] = 2
elif float(data_std[data_std['指标'] ==zb]['II']) > data[zb][num] >= float(data_std[data_std['指标'] ==zb]['III']):
data['%s_wq'%zb][num] = 3
elif float(data_std[data_std['指标'] ==zb]['III']) > data[zb][num] >= float(data_std[data_std['指标'] ==zb]['IV']):
data['%s_wq'%zb][num] = 4
elif float(data_std[data_std['指标'] ==zb]['IV']) > data[zb][num] >= float(data_std[data_std['指标'] ==zb]['V']):
data['%s_wq'%zb][num] = 5
elif (data[zb][num]) < float(data_std[data_std['指标'] ==zb]['V']):
data['%s_wq'%zb][num] = 6
else:
data['%s_wq'%zb][num] = np.NaN
data.head()





