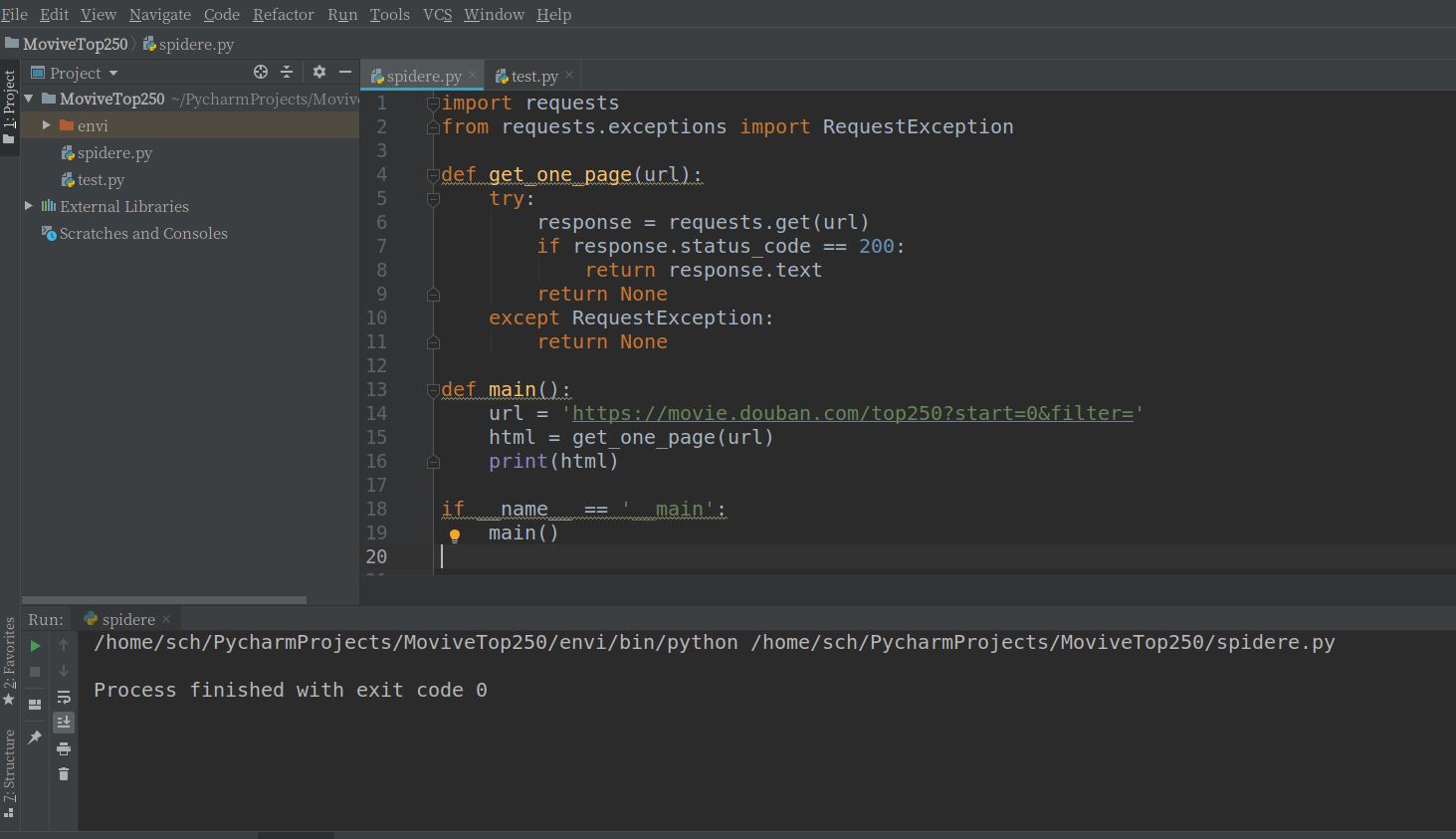
直接用requests.get就可以
response = requests.get("https://movie.douban.com/top250?start=0&filter=")
print(response.text)
但是我按照教程上的步骤就不可以,是我的代码哪里出了问题吗?
import requests
from requests.exceptions import RequestException
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def main():
url = 'https://movie.douban.com/top250?start=0&filter='
html = get_one_page(url)
print(html)
if __name__ == '__main':
main()