先附上代码
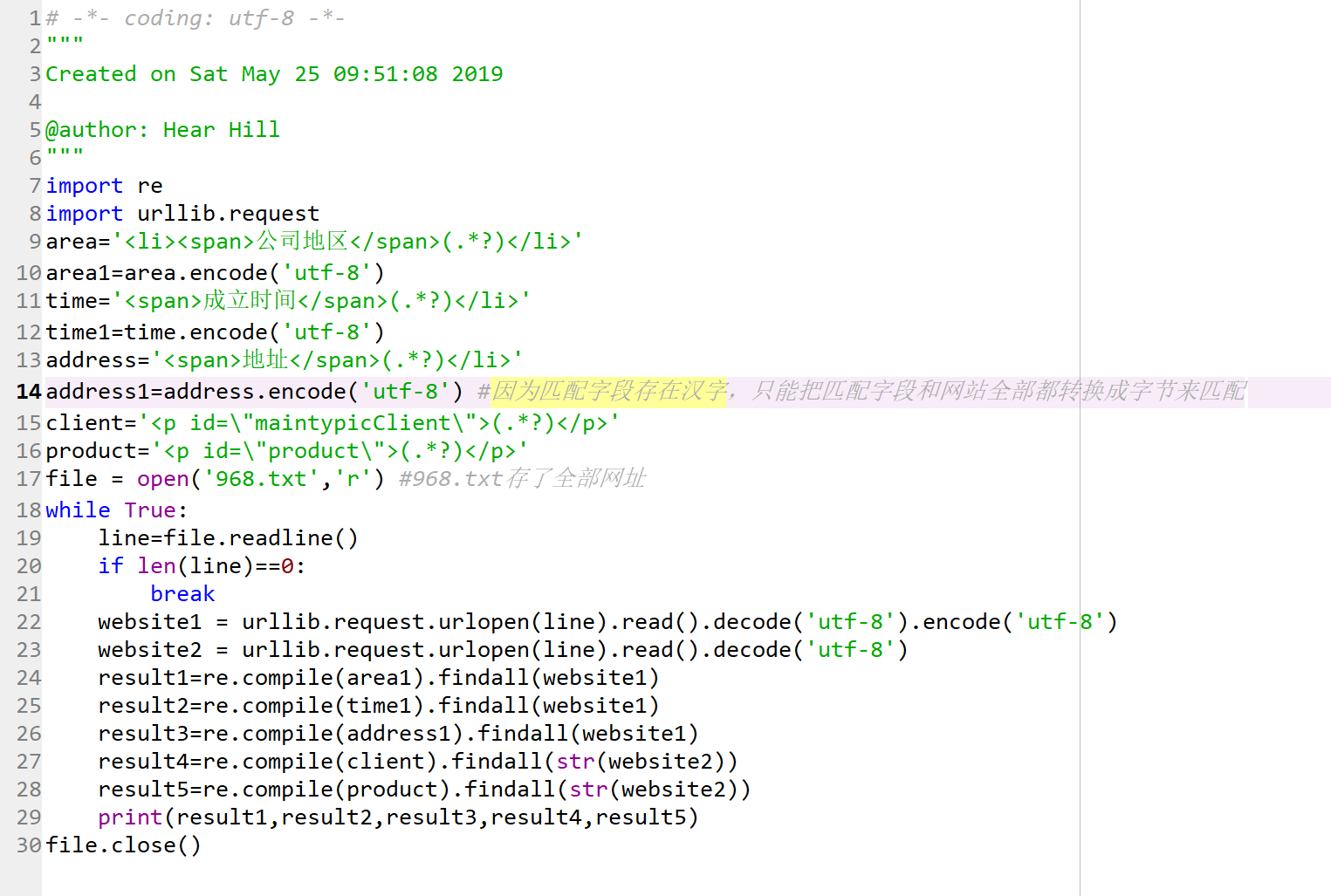
我想爬取网页上地区、时间等要素,现在这个程序是可以运行的,问题在result1、2、3上。因为这三个都是字节的匹配,所以结果也是字节。但因为compile得到的结果是list格式,所以结果都是[b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82']这样的格式,请问各位大佬有什么方法直接把他转为字符串吗?就像是上面这个直接转为他对应的汉字“北京市”。感谢大佬们

先附上代码
我想爬取网页上地区、时间等要素,现在这个程序是可以运行的,问题在result1、2、3上。因为这三个都是字节的匹配,所以结果也是字节。但因为compile得到的结果是list格式,所以结果都是[b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82']这样的格式,请问各位大佬有什么方法直接把他转为字符串吗?就像是上面这个直接转为他对应的汉字“北京市”。感谢大佬们
 分享
分享
a=b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82'
print(a.decode('utf-8'))
输出结果是‘’北京市‘’
对于你list中的元素 for i in range(list):list[i]=list[i].decode('utf-8')
分享



