
我想要这样的形式:
{"book_name": "XXXX", "writer": "XXX", "type": "XXX", "total_click": "XXX", "book_intro": "XXX", "label": ["XX", "XX", "XX", "XX"], "total_word_number": "XX ", "total_introduce": "XX", "week_introduce": "XX", "read_href": "XX", "chapters": [{"name": "第0001章 XX", "word_count": "XX", "time": "XX", "text": "XXXX"},{"name": "第0002章 XX", "word_count": "XX", "time": "XX", "text": "XXXX"},……]}
就像这样
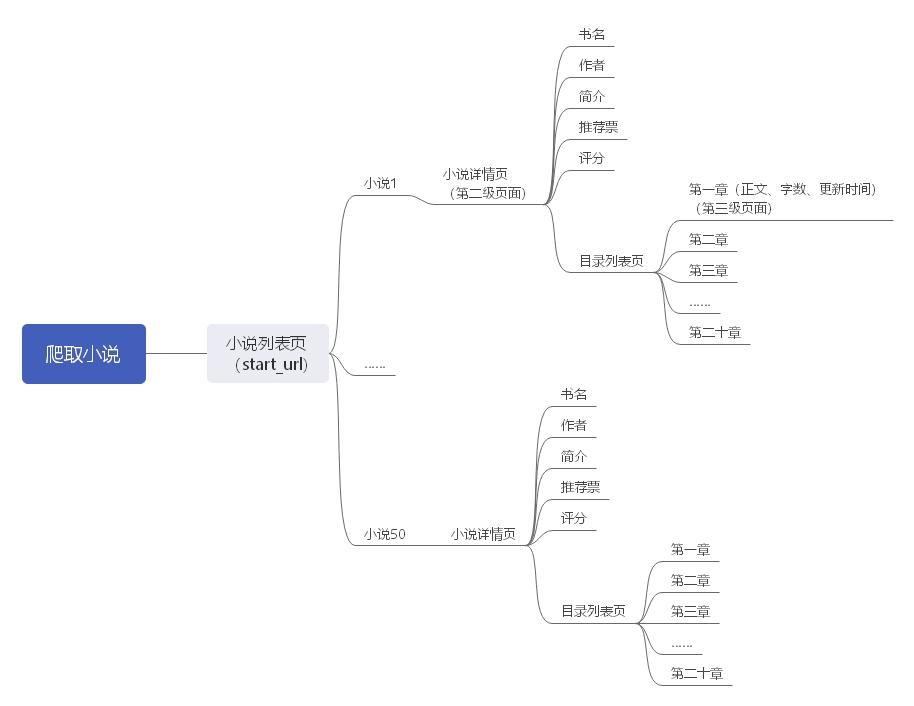
但是现在的结果不是章节在一个dict里面而是每章都返回一次item,我知道是哪里的逻辑有问题,但是不会改
代码如下
# -*- coding: utf-8 -*-
import scrapy
from novel.items import NovelItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
import re
url_page=1
class NovelSpider(CrawlSpider):
name = 'novel'
allowed_domains = ['book.zongheng.com']
custom_settings = {
"USER_AGENT": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36", }
start_urls = []
# for i in range(1,2):
i = 1
start_urls.append('http://book.zongheng.com/store/c0/c0/b0/u1/p' + str(i) +'/v9/s9/t0/u0/i1/ALL.html')
rules = (
Rule(LinkExtractor(allow=r'book/\d+'), callback="parse_detail"),
)
def parse_detail(self,response):
item = NovelItem()
item['book_name'] = response.css('div.book-name::text').extract_first()
item['writer'] = response.css("div.au-name a::text").extract_first()
item['type'] = response.css(
"body > div.wrap > div.book-html-box.clearfix > div.book-top.clearfix > div.book-main.fl > div.book-detail.clearfix > div.book-info > div.book-label > a.label::text").extract_first()
item['total_click'] = response.css(
"body > div.wrap > div.book-html-box.clearfix > div.book-top.clearfix > div.book-main.fl > div.book-detail.clearfix > div.book-info > div.nums > span:nth-child(3) > i::text").extract_first()
item['book_intro'] = response.css(
"body > div.wrap > div.book-html-box.clearfix > div.book-top.clearfix > div.book-main.fl > div.book-detail.clearfix > div.book-info > div********.book-dec.Jbook-dec.hide > p::text").extract_first()
item['label'] = response.xpath("//div[@class='book-label']/span/a/text()").extract()
item['total_word_number'] = response.xpath("//div[@class='nums']/span[1]/i/text()").extract_first()
item['total_introduce'] = response.xpath("//div[@class='nums']/span[2]/i/text()").extract_first()
item['week_introduce'] = response.xpath("//div[@class='nums']/span[4]/i/text()").extract_first()
read_href = response.css("div.btn-group>a::attr(href)").extract_first()
if read_href:
yield scrapy.Request(
read_href,
callback=self.parse_content,
dont_filter=True,
meta={"item": item},
)
def parse_content(self, response): # 处理正文
item = response.meta["item"]
chapters = []
chapter_name = response.css("div.title_txtbox::text").extract_first()
word_count = response.css("#readerFt > div > div.bookinfo > span:nth-child(2)::text").extract_first()
time = response.css("#readerFt > div > div.bookinfo > span:nth-child(3)::text").extract_first()
content_link = response.css("div.content")
paragraphs = content_link.css("p::text").extract()
content_text = ""
for i in range(0,len(paragraphs)):
content_text = content_text + paragraphs[i] + "\n"
content = dict(name=chapter_name,word_count=word_count,time=time,text=content_text)
chapters.append(content)
item['chapters'] = chapters#应该是这里出了问题,但是我不知道怎么解决
global url_page
url_page = url_page+1
next_page = response.css("a.nextchapter::attr(href)").extract_first()
if url_page<21:
yield scrapy.Request(
next_page,
callback=self.parse_content,
dont_filter = True,
meta = {"item": item},
)
# print(chapters)
yield item







