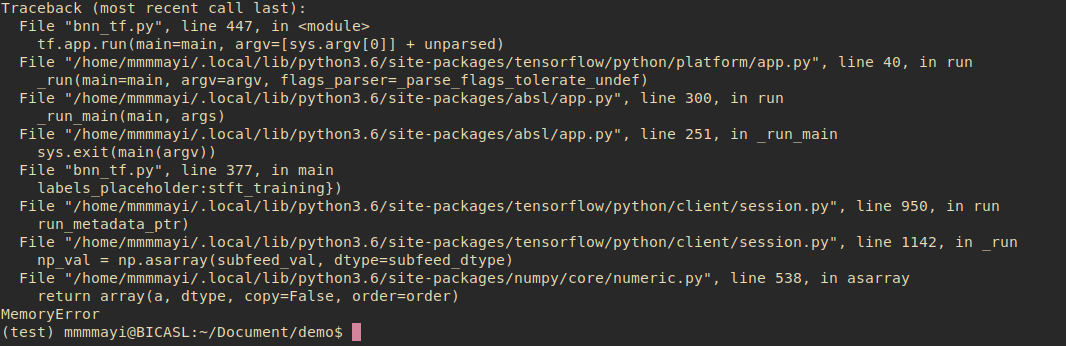
使用Tensorflow的API dataset的时候遇到了memoryerror,可是我是使用官方推荐的占位符的方法啊,我的系统是ubuntu 18.0.4,tensorflow 的版本是1.13.1,Python3.6,先上代码:
def main(_):
if FLAGS.self_test:
train_data, train_labels = fake_data(256)
validation_data, validation_labels = fake_data(EVAL_BATCH_SIZE)
test_data, test_labels = fake_data(EVAL_BATCH_SIZE)
num_epochs = 1
else:
stft_training, mfcc_training, labels_training = joblib.load(open(FLAGS.input, mode='rb'))
stft_training = numpy.array(stft_training)
mfcc_training = numpy.array(mfcc_training)
labels_training = numpy.array(labels_training)
stft_shape = stft_training.shape
stft_shape = (None, stft_shape[1], stft_shape[2])
mfcc_shape = mfcc_training.shape
mfcc_shape = (None, mfcc_shape[1], mfcc_shape[2])
labels_shape = labels_training.shape
labels_shape = (None)
stft_placeholder = tf.placeholder(stft_training.dtype, stft_shape)
labels_placeholder = tf.placeholder(labels_training.dtype, labels_shape)
mfcc_placeholder = tf.placeholder(mfcc_training.dtype, mfcc_shape)
dataset_training = tf.data.Dataset.from_tensor_slices((stft_placeholder, mfcc_placeholder, labels_placeholder))
dataset_training = dataset_training .apply(
tf.data.experimental.shuffle_and_repeat(len(stft_training), None))
dataset_training = dataset_training .batch(BATCH_SIZE)
dataset_training = dataset_training .prefetch(1)
iterator_training = dataset_training.make_initializable_iterator()
next_element_training = iterator_training.get_next()
num_epochs = NUM_EPOCHS
train_size = labels_training.shape[0]
stft = tf.placeholder(
data_type(),
shape=(BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WEITH, NUM_CHANNELS))
mfcc = tf.placeholder(
data_type(),
shape=(BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WEITH, NUM_CHANNELS))
labels = tf.placeholder(tf.int64, shape=(BATCH_SIZE,))
model = BRN(stft, mfcc)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
tf.global_variables_initializer().run()
train_writer = tf.summary.FileWriter(log_dir + 'train', sess.graph)
converter = tf.lite.TFLiteConverter.from_session(sess, [stft,mfcc], [logits])
tflite_model = converter.convert()
open("BRN.tflite", "wb").write(tflite_model)
print('Initialized!')
sess.run(iterator_training.initializer, feed_dict={stft_placeholder:stft_training,
mfcc_placeholder:stft_training,
labels_placeholder:stft_training})
报错信息: