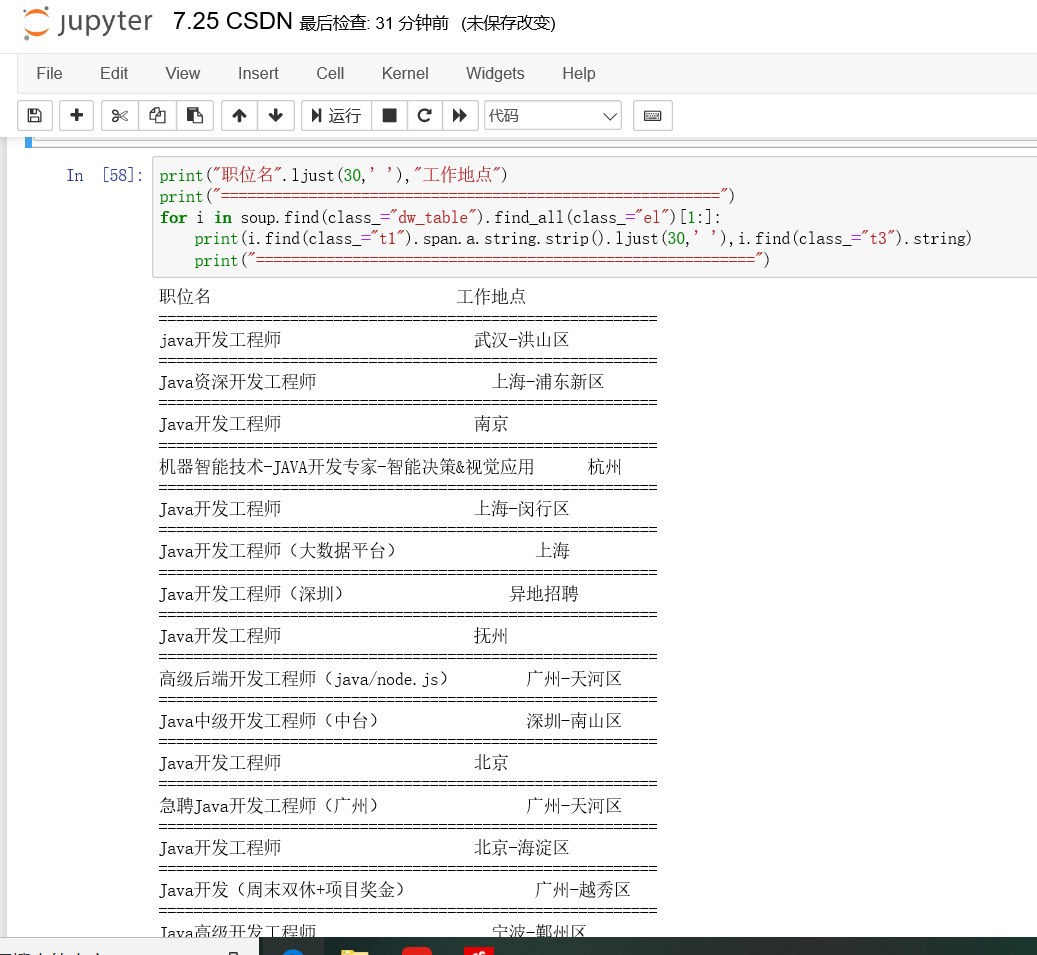
我想run这个出来两个list都是空的,想把工作名和地点弄下来,求解答怎么结局
import requests
from bs4 import BeautifulSoup
url = "https://search.51job.com/list/000000,000000,0000,00,9,99,Java%2520%25E5%25BC%2580%25E5%258F%2591,2,1.html?"
res = requests.get(url)
print(res)
res.encoding = "gbk"
soup = BeautifulSoup(res.text)
position_tag = soup.find_all("p",class_="t1")
print(position_tag)
place_tag = soup.find_all('span',class_='t3')
print(place_tag)