

我想要达到的结果
import requests
import re
import json
from bs4 import BeautifulSoup
def request_dandan(url):
try:
response=requests.get(url)
if response.status_code==200:
return response.text
except requests.RequestException:
return None
def write_item_to_fifle(item):
print("开始写入数据" + str(item))
with open("book.text",'a',encoding="utf-8") as f:
f.write(json.dumps(item,ensure_ascii=False)) + '\n'
f.close()
def main(page):
# 获取当当网好评榜页面html
url="http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-" + str(page)
html=request_dandan(url)
soup=BeautifulSoup(html,"lxml")
all_lis = soup.find_all('li')
for li in all_lis:
init_dict=[]
searchObj1 = re.search(r'list_num.*?(\d*?)\..*?>', str(li), re.M | re.I)
searchObj2 = re.search(r'<div class="name">.*?title="(.*?)">.*?>', str(li), re.M | re.I)
searchObj3 = re.search(r'<div class="publisher_info">.*?title="(.*?)">.*?>', str(li), re.M | re.I)
# 书名与出版信息非空时,将匹配结果赋值给字典
if searchObj1 and searchObj2 and searchObj3:
init_dict["list_num"] = searchObj1.group(1)
init_dict["name"] = searchObj2.group(1)
init_dict["publisher_info"] = searchObj3.group(1)
if init_dict:
write_item_to_fifle(init_dict)
if __name__ == "__main__":
for i in range(1,26):
main(i)
`
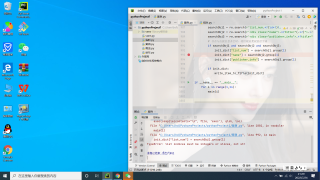
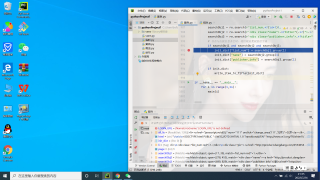
请问是这样调试不









