
参照这个代码,会产生一个网页。网页上可以做语义搜索。现在我运行这个python程序,网页打不开。
from sentence_transformers import SentenceTransformer
from flask import Flask, request, render_template
import scipy
import os
import pandas as pd
import keras.backend.tensorflow_backend as tb
#import tensorflow.python.keras.backend as tb
#from keras.backend import set_session as tb
#from tensorflow.keras.models import model_from_json
from keras.models import model_from_json
#tb._SYMBOLIC_SCOPE.value = True
# Load the BERT model. Various models trained on Natural Language Inference (NLI) https://github.com/UKPLab/sentence-transformers/blob/master/docs/pretrained-models/nli-models.md and
# Semantic Textual Similarity are available https://github.com/UKPLab/sentence-transformers/blob/master/docs/pretrained-models/sts-models.md
model = SentenceTransformer('bert-base-nli-mean-tokens')
# setting up template directory
TEMPLATE_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'templates')
app = Flask(__name__, template_folder=TEMPLATE_DIR, static_folder=TEMPLATE_DIR)
#app = Flask(__name__)
@app.route("/")
def hello():
return TEMPLATE_DIR
# A corpus is a list with documents split by sentences.
BASE_DIR = '/Volumes/My Passport for Mac/data'
TEXT_DATA_DIR = os.path.join(BASE_DIR, 'million-news-dataset')
NEWS_FILE_NAME = "abcnews-date-text.csv"
def read_csv(filepath):
if os.path.splitext(filepath)[1] != '.csv':
return # or whatever
seps = [',', ';', '\t'] # ',' is default
encodings = [None, 'utf-8', 'ISO-8859-1'] # None is default
for sep in seps:
for encoding in encodings:
try:
return pd.read_csv(filepath, encoding=encoding, sep=sep)
except Exception: # should really be more specific
pass
raise ValueError("{!r} is has no encoding in {} or seperator in {}"
.format(filepath, encodings, seps))
# A corpus is a list with documents split by sentences.
#BASE_DIR = '/Volumes/My Passport for Mac/data'
#TEXT_DATA_DIR = os.path.join(BASE_DIR, 'million-news-dataset')
#NEWS_FILE_NAME = "abcnews-date-text.csv"
#input_df = read_csv(os.path.join(TEXT_DATA_DIR, NEWS_FILE_NAME))
#input_df = input_df.head(20000)
#print(input_df.head(20))
#sentences = input_df['headline_text'].values.tolist()
sentences = ['aba decides against community broadcasting licence',
'act fire witnesses must be aware of defamation',
'a g calls for infrastructure protection summit',
'air nz staff in aust strike for pay rise',
'air nz strike to affect australian travellers',
'ambitious olsson wins triple jump',
'antic delighted with record breaking barca',
'aussie qualifier stosur wastes four memphis match',
'aust addresses un security council over iraq',
'australia is locked into war timetable opp',
'australia to contribute 10 million in aid to iraq']
# Each sentence is encoded as a 1-D vector with 78 columns
print("Getting embeddings for sentences ....")
sentence_embeddings = model.encode(sentences)
print("done with getting embeddings for sentences ....")
print('Sample BERT embedding vector - length', len(sentence_embeddings[0]))
#print('Sample BERT embedding vector - note includes negative values', sentence_embeddings[0])
def performSearch(query):
queries = [query]
query_embeddings = model.encode(queries)
# Find the closest 3 sentences of the corpus for each query sentence based on cosine similarity
number_top_matches = 3 #@param {type: "number"}
print("Semantic Search Results")
results = []
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], sentence_embeddings, "cosine")[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
return results
@app.route("/semanticsearch", methods=['GET', 'POST'])
def rec():
query = ''
if(request.method == "POST"):
print("inside post")
query = request.form.get('query')
print(query)
results = performSearch(query)
return render_template('semantic_search.html', query=query, results=results, sentences=sentences)
else:
return render_template('semantic_search.html', review="" ,results=None)
if __name__ == "__main__":
app.run(host='127.0.0.1',port=9200, debug=True, threaded=True)
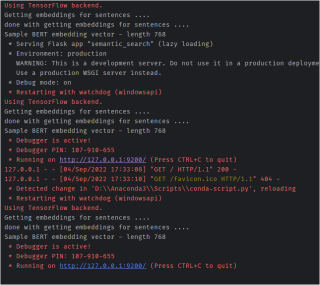
我在网址栏中输入 http://127.0.0.1:9200/并没有得到网站。而是得到

有没有专家告诉我,大概出了什么问题呢?








