
如第一张图所示,已经拥有ISSN,通过搜索框输入后,对结果栏(如第二张图所示)里面的一些指标包括影响因子、官网等进行提取,在通过request提取后,发现找不到这些指标对应的class,代码如第三张图所示,最终想得到的信息如第四张图所示。初学python,问题比较愚蠢还请见谅。
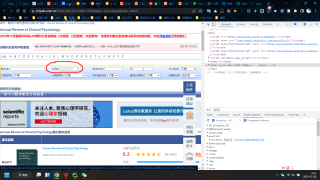
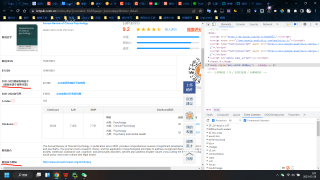


如第一张图所示,已经拥有ISSN,通过搜索框输入后,对结果栏(如第二张图所示)里面的一些指标包括影响因子、官网等进行提取,在通过request提取后,发现找不到这些指标对应的class,代码如第三张图所示,最终想得到的信息如第四张图所示。初学python,问题比较愚蠢还请见谅。
 分享
分享
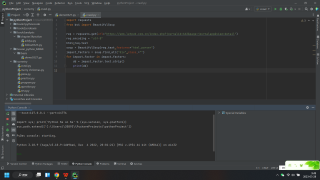
你需要现在网页html中看下那些指标因子的html结构是什么,才知道怎么提取。你的数据是在一个表格中,你可以先定位到表格的html,然后通过前后html标签来定位到你要解析的数据。代码如下,已成功提取,望采纳!
import requests
from bs4 import BeautifulSoup
import re
req = requests.get(url="https://www.letpub.com.cn/index.php?journalid=662&page=journalapp&view=detail")
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(html,'lxml')
#先定位数据所在的table
table_htmls = soup.find_all('table',attrs={'class':'table_yjfx'})
tr = table_htmls[1].find('td',string=re.compile("E-ISSN"))
print(tr.parent.next_sibling.contents[1].get_text())
td_2 = table_htmls[1].find('td',string="期刊官方网站")
if td_2:
print(td_2.next_sibling.a['href'])
最后成功提取你要的数据:
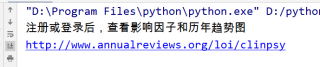
分享 系统已结题
4月5日
系统已结题
4月5日 已采纳回答
3月28日
创建了问题
3月28日
已采纳回答
3月28日
创建了问题
3月28日

