
Hi 大家好啊:
我在写一个挖掘 “某网站上产品价格” 的程序。
之前在各路高手的帮助下,已经能捕捉到同一型号下 不同子型号的功能了
如 下面2张图片这样:
(获取网页中 某类型产品 下 4个不同的子类型 名称信息)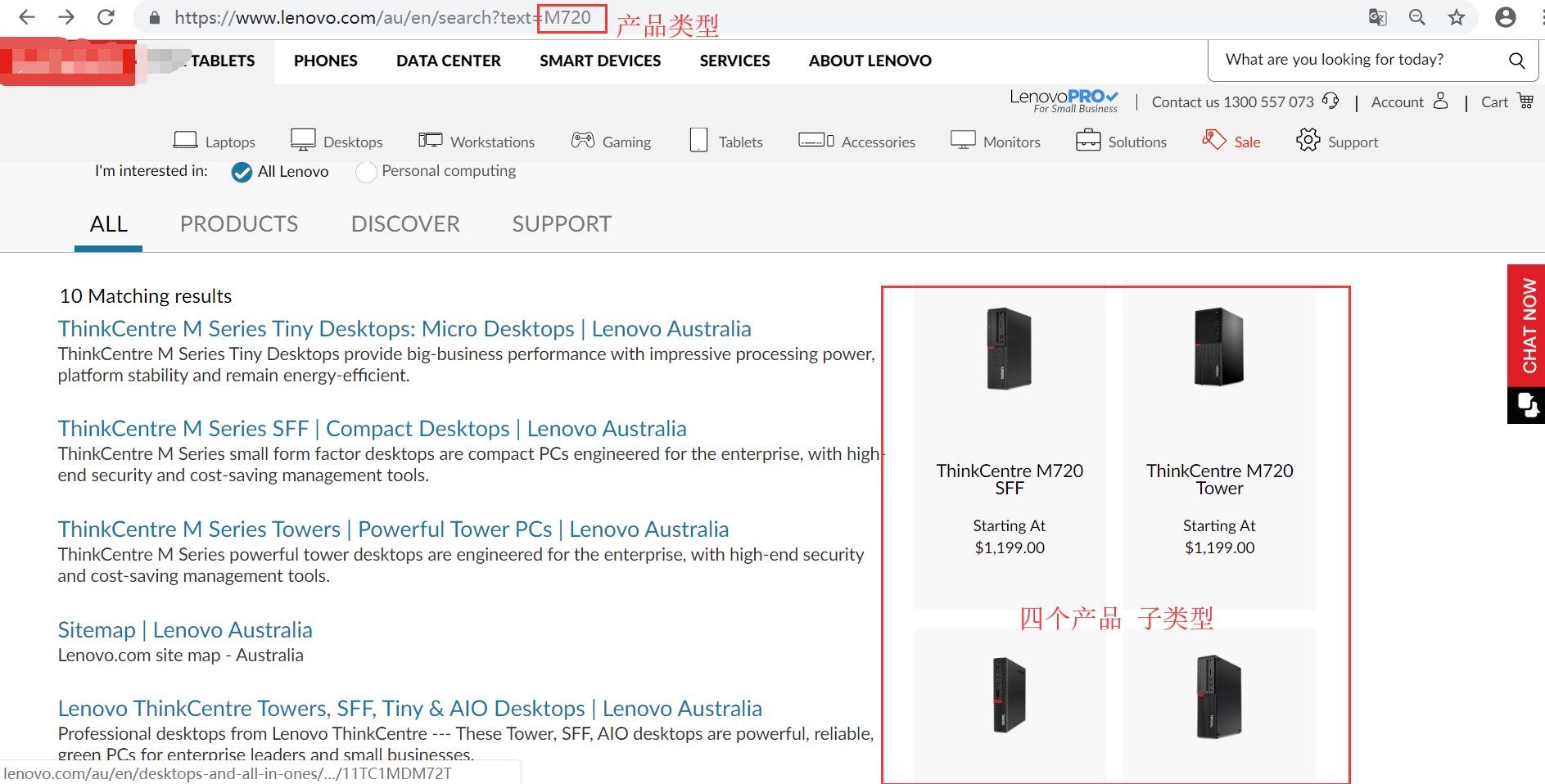
(返回值如下:)

目前,我的代码是这样的:
from bs4 import BeautifulSoup
import requests
url='https://www.lenovo.com/au/en/search?text=M720' # 这个是搜索 M720 时候的 返回网站
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'}
# ok 至少 header 是没有问题的,可以进得去
def get_machine_infro():
wb_data = requests.get(url,headers=headers) #使用 url 和 header 打开网页
soup=BeautifulSoup(wb_data.text,'lxml')
machin=soup.select('.o-productCard__content h3 a') # 网页源代码 机型处 前面的 网页码 注意 这个要选择那个唯一的
#machin=soup.select('.o-productCard__content')
for i in range(len(machin)):
print(machin[i].text) # 打印处 网页中全部的 机型名称
get_machine_infro()
现在 我想更进一步: 去分别查看这些“子型号”产品下面的具体信息。
也许,可以是类似我们通过点击“Learn more” 按钮所实现的那种跳转(如下面的图片), 或者其他的方法...?
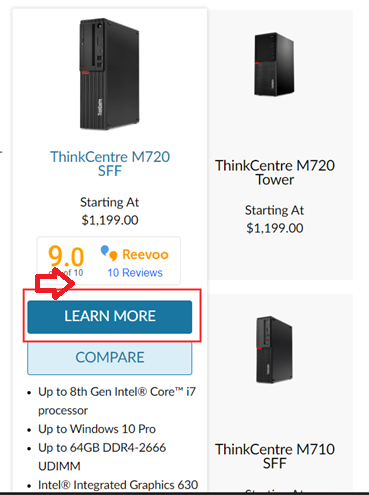
请问 要实现这种 针对 代码中已经获取的这些“子类型“跳转到相应的子页面的功能 我们应该如何实现呢?
谢谢各位大佬不吝赐教







