我想采集到下面这个黄色格子里的内容.但是网页上面这2行是相当于1行的.
内容是:
913我用xpath://table[@class='pub_table']/tbody[1]/tr[2]/td[4]采集出来是913,
试了N次,都不能单独的采集出来13.
我只想采集13,这个应该怎么弄啊?
这个是网址:http://odds.500.com/fenxi/bifen-869554.shtml
就是 表格左上角的 9 和13
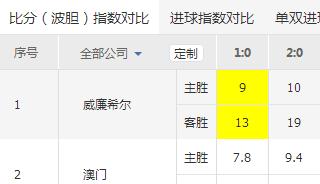

我想采集到下面这个黄色格子里的内容.但是网页上面这2行是相当于1行的.
内容是:
913我用xpath://table[@class='pub_table']/tbody[1]/tr[2]/td[4]采集出来是913,
试了N次,都不能单独的采集出来13.
我只想采集13,这个应该怎么弄啊?
这个是网址:http://odds.500.com/fenxi/bifen-869554.shtml
就是 表格左上角的 9 和13
 分享
分享




