
我现在正在尝试通过php curl来得取淘宝的价格和特征
在通过搜寻资料,我大约理解了他是需要通过他自己本来的Link
来去请求资料,所以我有些个referer去读取
以下是我代码的最新进度。
$ch = curl_init();
$options = array(
CURLOPT_URL => $html_brand,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HEADER => false,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_SSL_VERIFYPEER => false,
CURLOPT_AUTOREFERER => true,
CURLOPT_CONNECTTIMEOUT => 15,
CURLOPT_TIMEOUT => 300,
CURLOPT_MAXREDIRS => 10,
CURLOPT_USERAGENT => 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.47 Safari/536.11',
CURLOPT_REFERER => 'https://item.taobao.com/item.htm?spm=a21wu.241046-us.4691948847.15.41cab6cbjntFdJ&scm=1007.15423.84311.100200300000005&id=559773018599&pvid=fdb60901-5683-498d-889f-3d4ed883c8c7',
);
curl_setopt_array($ch, $options);
$response = curl_exec($ch);
curl_close($ch);
print_r($response);
我得到的返回是这个,如果我没有推测错的话,他应该是类似要登录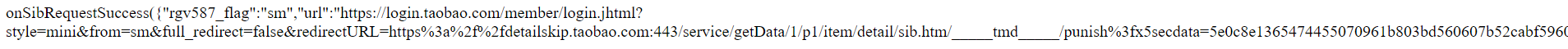
但是我在找资料的时候看别人代码中都没有指定要求要登录才能截取
想请问我的逻辑里是缺少了什么吗。我是因为缺少什么导致资料得取不了







