
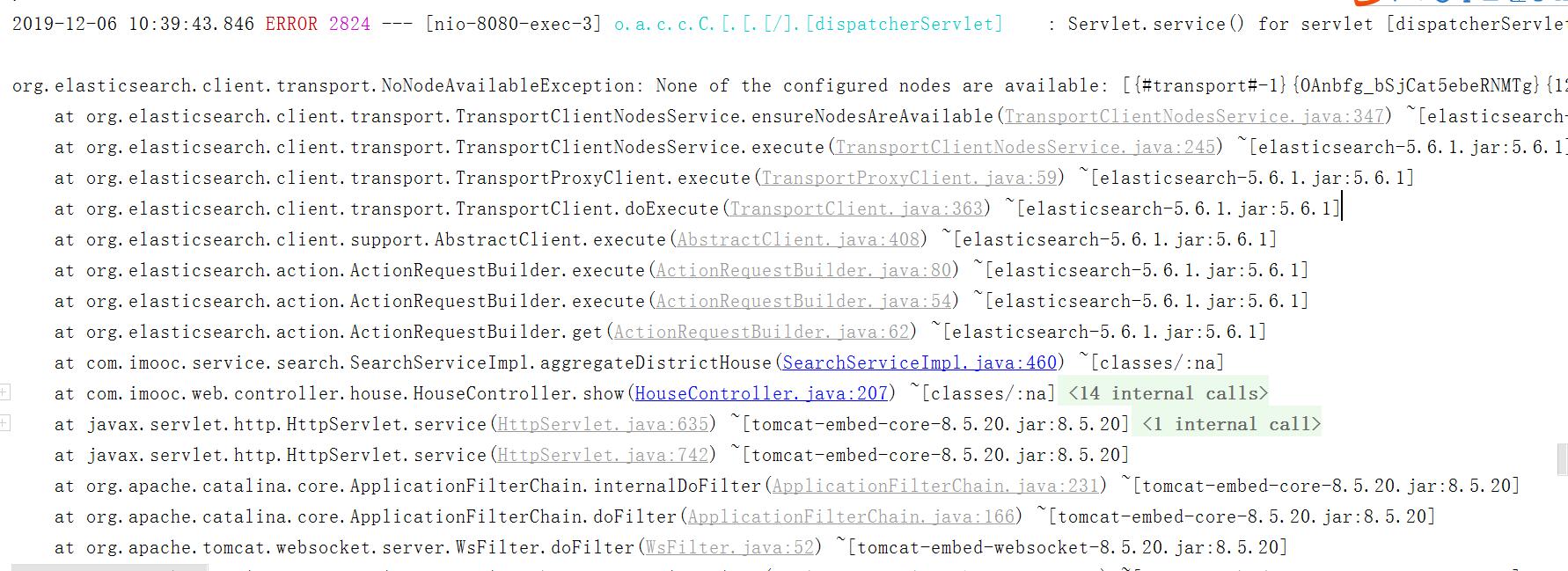
1、错误截图
2019-12-06 10:39:43.846 ERROR 2824 --- [nio-8080-exec-3] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is NoNodeAvailableException[None of the configured nodes are available: [{#transport#-1}{OAnbfg_bSjCat5ebeRNMTg}{127.0.0.1}{127.0.0.1:9300}]]] with root cause
org.elasticsearch.client.transport.NoNodeAvailableException: None of the configured nodes are available: [{#transport#-1}{OAnbfg_bSjCat5ebeRNMTg}{127.0.0.1}{127.0.0.1:9300}]
at org.elasticsearch.client.transport.TransportClientNodesService.ensureNodesAreAvailable(TransportClientNodesService.java:347) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.client.transport.TransportClientNodesService.execute(TransportClientNodesService.java:245) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.client.transport.TransportProxyClient.execute(TransportProxyClient.java:59) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.client.transport.TransportClient.doExecute(TransportClient.java:363) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.client.support.AbstractClient.execute(AbstractClient.java:408) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.action.ActionRequestBuilder.execute(ActionRequestBuilder.java:80) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.action.ActionRequestBuilder.execute(ActionRequestBuilder.java:54) ~[elasticsearch-5.6.1.jar:5.6.1]
at org.elasticsearch.action.ActionRequestBuilder.get(ActionRequestBuilder.java:62) ~[elasticsearch-5.6.1.jar:5.6.1]
at com.imooc.service.search.SearchServiceImpl.aggregateDistrictHouse(SearchServiceImpl.java:460) ~[classes/:na]
at com.imooc.web.controller.house.HouseController.show(HouseController.java:207) ~[classes/:na]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_131]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_131]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_131]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_131]
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:205) ~[spring-web-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:133) ~[spring-web-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:97) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:827) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:738) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:85) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:967) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:901) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:970) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:861) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:635) ~[tomcat-embed-core-8.5.20.jar:8.5.20]
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:846) ~[spring-webmvc-4.3.11.RELEASE.jar:4.3.11.RELEASE]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:742) ~[tomcat-embed-core-8.5.20.jar:8.5.20]
2、elasticsearch配置信息
cluster.name: elasticsearch
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: master
node.master: true
node.data: true
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 127.0.0.1
#
# Set a custom port for HTTP:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.zen.ping.unicast.hosts: ["host1", "host2"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes: 3
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
#bootstrap.system_call_filter: false
http.cors.enabled: true
http.cors.allow-origin: "*"
3、spring项目配置信息
package com.imooc.config;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.net.InetAddress;
import java.net.UnknownHostException;
@Configuration
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String esHost;
@Value("${elasticsearch.port}")
private int esPort;
@Value("${elasticsearch.cluster.name}")
private String esName;
@Bean
public TransportClient esClient() throws UnknownHostException {
Settings settings = Settings.builder()
.put("cluster.name", this.esName)
// .put("cluster.name", "elasticsearch")
.put("client.transport.sniff", true)
.build();
InetSocketTransportAddress master = new InetSocketTransportAddress(
InetAddress.getByName(esHost), esPort
// InetAddress.getByName("192.168.100.106"), 8999
);
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(master);
return client;
}
}
4、application.propertires
elasticsearch.cluster.name=xunwu
elasticsearch.host=127.0.0.1
elasticsearch.port=9300





