
先截图说明下整个查询的需求和用到的表格:
如图,查询的条件包括“区域”,“地衣芽孢杆菌”,“2018”,
查询的结果是图中下方的表格,包含“区域”,“采样数量”,“地衣芽孢杆菌数量”等字段;

如图,表格是云南塞优(西南的唯一一个牧场)的三个采集样本,每一个元组,即每一个采集样本对应一个表格,如下图,是序号1的样本对应的分离菌株表格
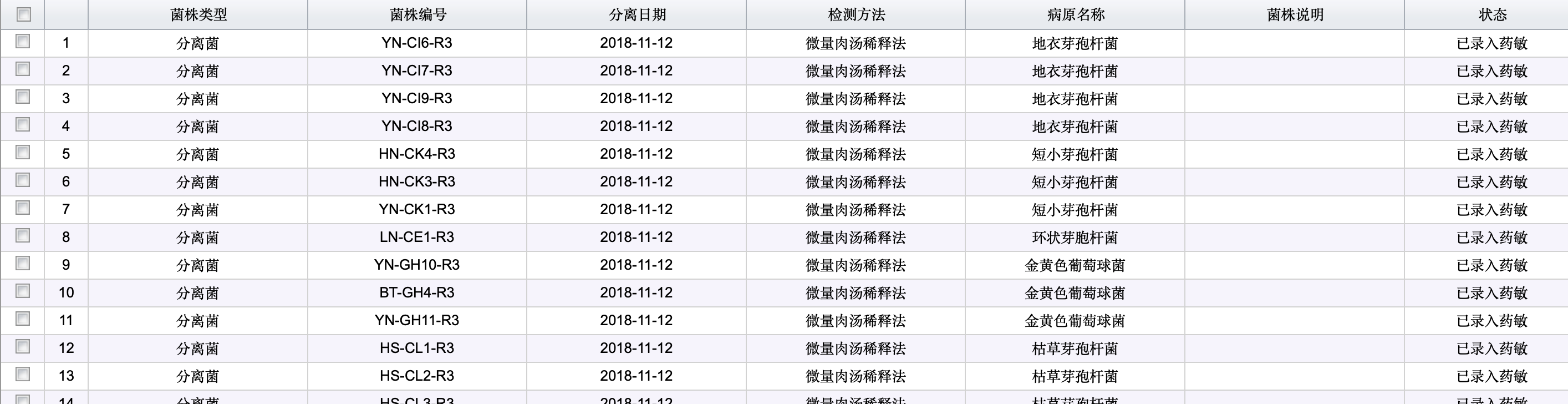
如图,病原菌名称是地衣芽孢杆菌的有四个,序号为2和3的分离菌株表格中没有地衣芽孢杆菌,所以查询后得到的结果中,地衣芽孢杆菌数量是4,分离出地衣芽孢杆菌的样本数是1
如上所述,就是整个查询过程和结果。查询的SQL语句该怎么写,实在是想不出。
本人看了SQL在表连接、嵌套查询等的教材和帖子,还是没有找到和我这个情况比较类似的,数据库新手,请大神指教!





