
编写的python小程序,爬取豆瓣评论,昨天还可以用,今天就失效了,试过很多种解决方法,都没有成功,求教?
可能的问题是ip被封或者cookies?
主程序
# -*- coding: utf-8 -*-
import ReviewCollection
from snownlp import SnowNLP
from matplotlib import pyplot as plt
#画饼状图
def PlotPie(ratio, labels, colors):
plt.figure(figsize=(6, 8))
explode = (0.05,0)
patches,l_text,p_text = plt.pie(ratio,explode=explode,labels=labels,colors=colors,
labeldistance=1.1,autopct='%3.1f%%',shadow=False,
startangle=90,pctdistance=0.6)
plt.axis('equal')
plt.legend()
plt.show()
def main():
#初始url
url = 'https://movie.douban.com/subject/30176393/'
#保存评论文件
outfile = 'review.txt'
(reviews, sentiment) = ReviewCollection.CollectReivew(url, 20, outfile)
numOfRevs = len(sentiment)
print(numOfRevs)
#print(sentiment)
positive = 0.0
negative = 0.0
accuracy = 0.0
#利用snownlp逐条分析每个评论的情感
for i in range(numOfRevs):
# if sentiment[i] == 1:
# positive += 1
# else:
# negative += 1
print(reviews[i]+str(i))
sent = SnowNLP(reviews[i])
predict = sent.sentiments
#print(predict,end=' ')
if predict >= 0.5:
positive += 1
if sentiment[i] == 1:
accuracy += 1
else:
negative += 1
if sentiment[i] == 0:
accuracy += 1
#计算情感分析的精度
print('情感预测精度为: ' + str(accuracy/numOfRevs))
# print(positive,negative)
#绘制饼状图
#定义饼状图的标签
labels = ['Positive Reviews', 'Negetive Reviews']
#每个标签占的百分比
ratio = [positive/numOfRevs, negative/numOfRevs]
# print(ratio[0],ratio[1])
colors = ['red','yellowgreen']
PlotPie(ratio, labels, colors)
if __name__=="__main__":
main()
次程序
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import csv
import re
import time
import codecs
import random
def StartoSentiment(star):
'''
将评分转换为情感标签,简单起见
我们将大于或等于三星的评论当做正面评论
小于三星的评论当做负面评论
'''
score = int(star[-2])
if score >= 3:
return 1
else:
return 0
def CollectReivew(root, n, outfile):
'''
收集给定电影url的前n条评论
'''
reviews = []
sentiment = []
urlnumber = 0
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36','Connection': 'close','cookie': 'll="108303"; bid=DOSjemTnbi0; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.1517093765.1576143949.1576143949.1576143949.1; __utmb=30149280.0.10.1576143949; __utmc=30149280; __utmz=30149280.1576143949.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1844590374.1576143949.1576143949.1576143949.1; __utmc=223695111; __utmz=223695111.1576143949.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1; __yadk_uid=iooXpNnGnHUza2r4ru7uRCpa3BXeHG0l; dbcl2="207917948:BFXaC6risAw"; ck=uFvj; _pk_id.100001.4cf6=4c11da64dc6451d3.1576143947.1.1576143971.1576143947.; __utmb=223695111.2.10.1576143949'}
proxies = { "http":'http://121.69.46.177:9000',"https": 'https://122.136.212.132:53281'}#121.69.46.177:9000218.27.136.169:8085 122.136.212.132:53281
while urlnumber < n:
url = root + 'comments?start=' + str(urlnumber) + '&limit=20&sort=new_score&status=P'
print('要收集的电影评论网页为:' + url)
# try:
html = requests.get(url, headers = headers, proxies = proxies,timeout = 15) #
# except Exception as e:
# break
soup = BeautifulSoup(html.text.encode("utf-8"),'html.parser')
#通过正则表达式匹配评论和评分
for item in soup.find_all(name='span',attrs={'class':re.compile(r'^allstar')}):
sentiment.append(StartoSentiment(item['class'][0]))
#for item in soup.find_all(name='p',attrs={'class':''}):
# if str(item).find('class="pl"') < 0:
# r = str(item.string).strip()
# reviews.append(r)
comments = soup.find_all('span','short')
for comment in comments:
# print(comment.getText()+'\n')
reviews.append(comment.getText()+'\n')
urlnumber = urlnumber + 20
time.sleep(5)
with codecs.open(outfile, 'w', 'utf-8') as output:
for i in range(len(sentiment)):
output.write(reviews[i] + '\t' + str(sentiment[i]) + '\n')
return (reviews, sentiment)
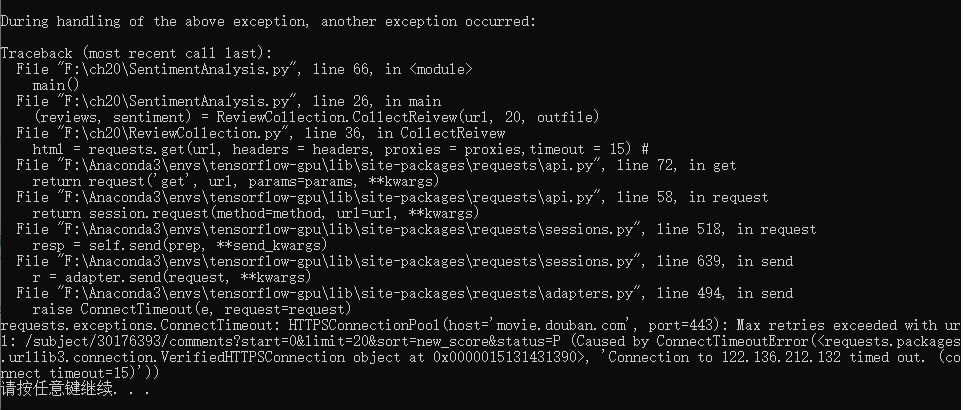
不设置参数proxies时错误如下: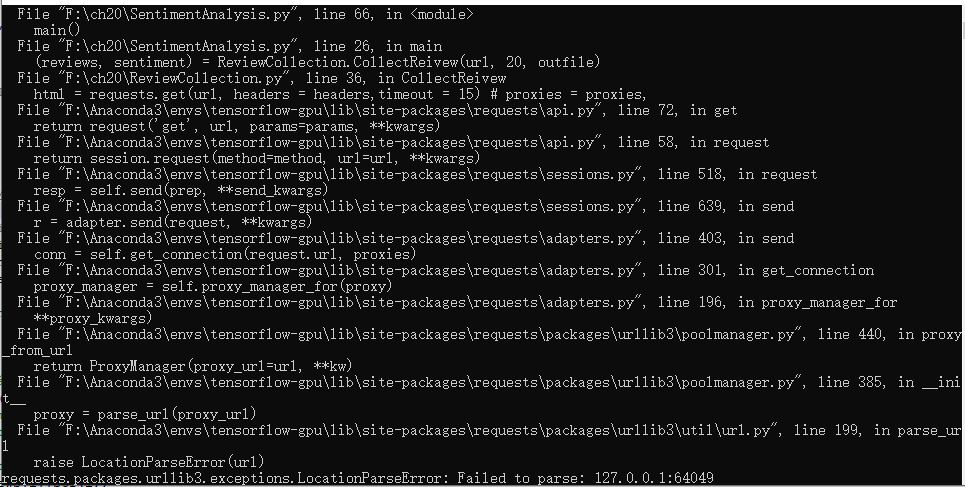
求教解决方法,感谢!!!!




