我刚学几天python,我也不会啊,
求源代码
简单的就可以,能把彩虹岛游戏官网主页爬取出来
运行成功就可以
谢谢您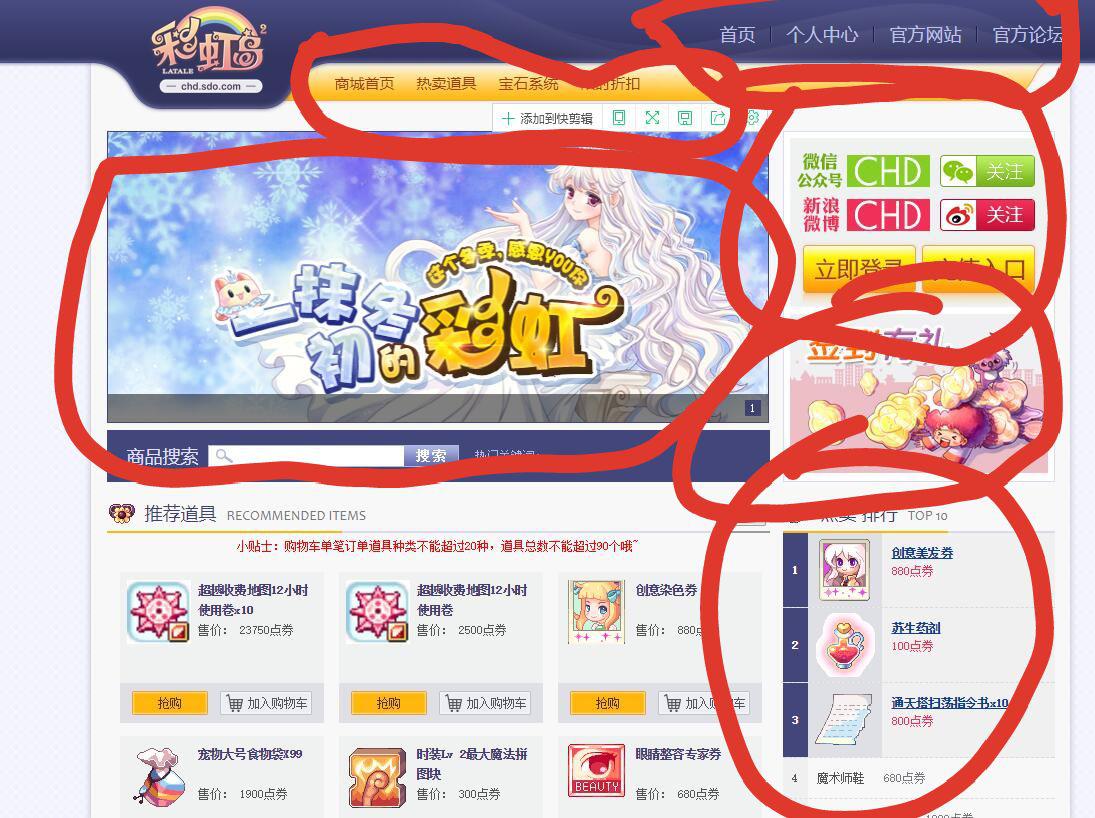
救一救孩子吧,挂科了要
谢谢您。

救救孩子吧,用requests+re爬取彩虹岛主页信息

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-



2条回答 默认 最新
 bj_0163_bj 2019-12-18 02:44关注
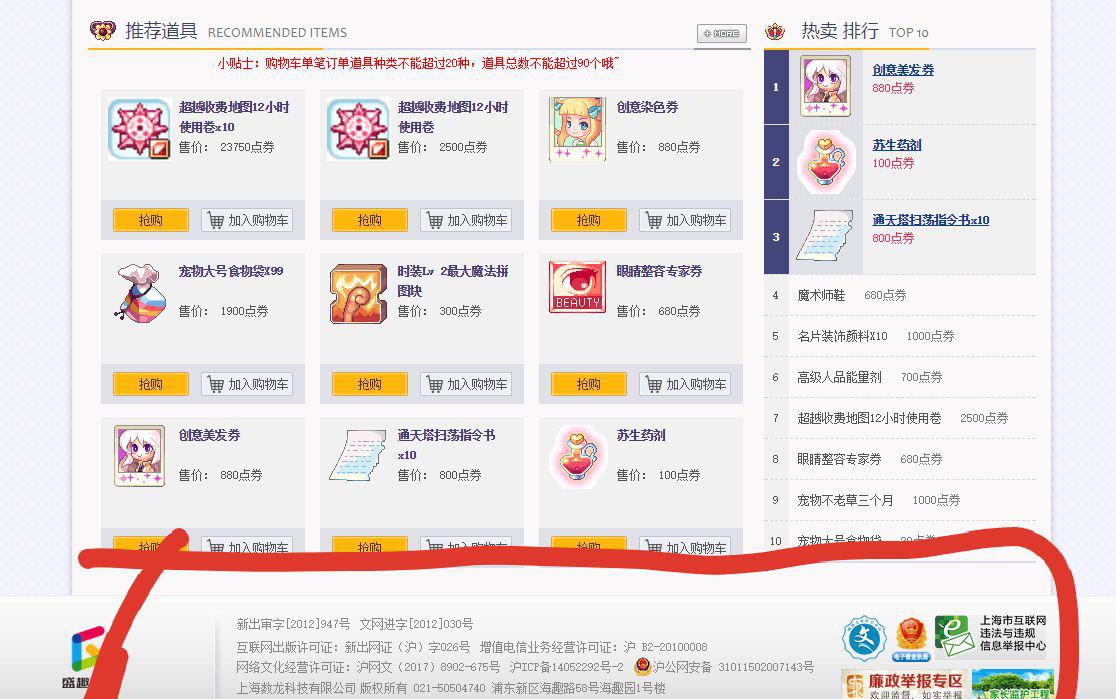
bj_0163_bj 2019-12-18 02:44关注帮你把主页里面游戏名字爬出来了
import requests import re url = 'http://tmall.chd.sdo.com/' res= requests.get(url) lt=re.findall('<h4 class="title"><a target="_blank" href="http://tmall.chd.sdo.com/Shop/Detail/[0-9]+\">(.*?)</a></h4>',res.text,re.S) print(lt)本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享

悬赏问题
- ¥30 SD中的一段Unet下采样代码其中的resnet是谁跟谁进行残差连接
- ¥15 Unet采样阶段的res_samples问题
- ¥60 Python+pygame坦克大战游戏开发实验报告
- ¥15 R语言regionNames()和demomap()无法选中中文地区的问题
- ¥15 Open GL ES 的使用
- ¥15 我如果只想表示节点的结构信息,使用GCN方法不进行训练可以吗
- ¥15 QT6将音频采样数据转PCM
- ¥15 下面三个文件分别是OFDM波形的数据,我的思路公式和我写的成像算法代码,有没有人能帮我改一改,如何解决?
- ¥15 Ubuntu打开gazebo模型调不出来,如何解决?
- ¥100 有chang请一位会arm和dsp的朋友解读一个工程