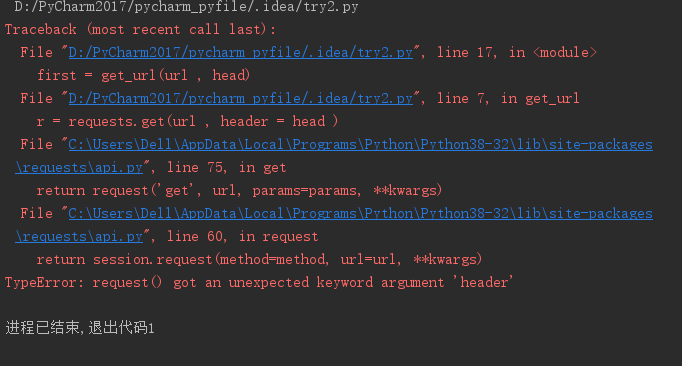
爬虫遇到的困难,反 爬 取 为什么会出像这样的问题?这个有什么问题吗?
import requests
from bs4 import BeautifulSoup
import bs4
def get_url(url , header):#获得网页内容
r = requests.get(url , header = head , timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return print(r.text ,r.status_code)
if __name__ == '__main__':
url = "https://www1.nm.zsks.cn/xxcx/gkcx/lqmaxmin_19.jsp"
head = {'Cookie':'BIGipServerweb_pool=2181103882.36895.0000; JSESSIONID=v0VlpLwW0lzXx1R3n44xvMpYD8hWvJgLhZ8ccZwTzZ5N1LJn1L0l!-1640068139',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'}
first = get_url(url , head)
pass