
我是用的谷歌浏览器,按f12后经过对比,我发现我代码requests.get返回的是——sources里面的html文本,但我想要的是element里面的html文本,怎么才能返回正确的html呢?
↓这是我想要找的: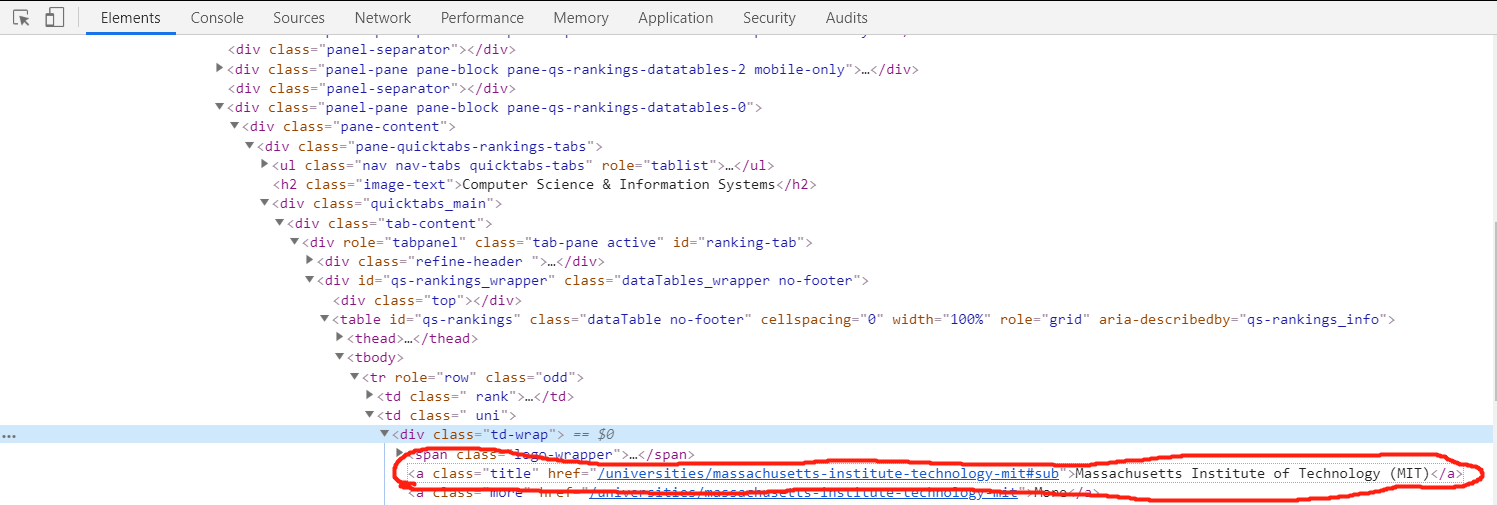
但是返回的却是这个: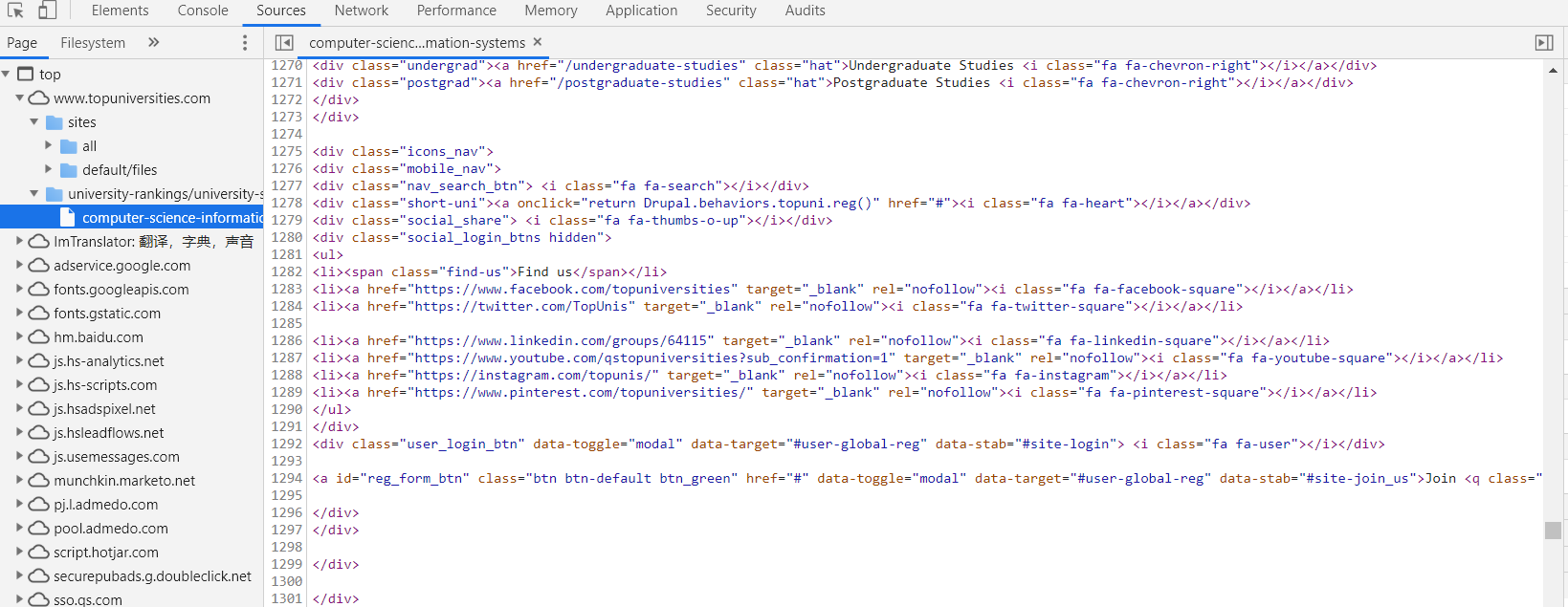
然后我写的代码是这个: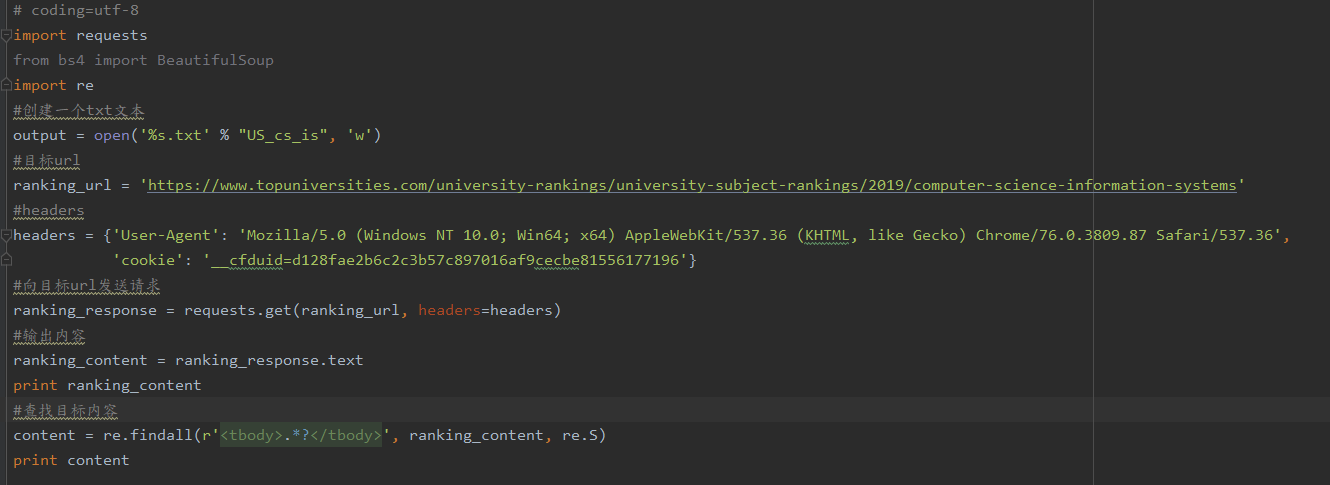
请问该怎么解决这种情况呢??

我是用的谷歌浏览器,按f12后经过对比,我发现我代码requests.get返回的是——sources里面的html文本,但我想要的是element里面的html文本,怎么才能返回正确的html呢?
↓这是我想要找的:
但是返回的却是这个:
然后我写的代码是这个:
请问该怎么解决这种情况呢??
 分享
分享
用request的get方法得到的是服务器返回给你的源码,而你用f12调试看到的是浏览器解释过后的代码,不一样是正常的,要获取f12看到的可以用selenium模拟访问
分享
