import urllib.request
import urllib.parse
import re
from bs4 import BeautifulSoup
import chardet
def main():
keyword=input("请输入关键词:")
keyword=urllib.parse.urlencode({"word":keyword})
response= \
urllib.request.urlopen("https://baike.baidu.com/search/word?%s"%\
keyword)
html=response.read()
soup=BeautifulSoup(html,"html.parser")
for each in soup.find_all(href=re.compile("view")):
content=''.join([each.text])
** url2 = ''.join(["https://baike.baidu.com", each["href"]])**
print(chardet.detect(str.encode(url2)))
response2 = urllib.request.urlopen(url2)
html2 = response2.read()
soup2 = BeautifulSoup(html2, "html.parser")
if soup2.h2:
content = ''.join([content, soup2.h2.text])
content = ''.join([content, "->", url2])
print(content)
if name=="__main__":
main()
我测试了一下,发现从 url2 = ''.join(["https://baike.baidu.com", each["href"]])这一句开始,它并没有全部编码成utf-8,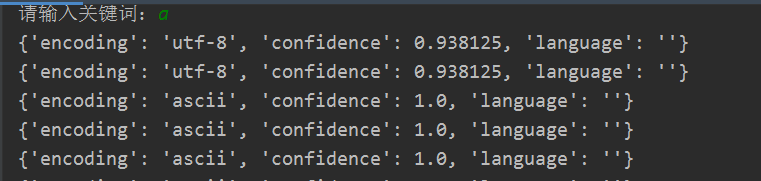 然后我用了encode转为utf-8还是不行,被折磨了一下午了,头都大了,请问有大哥能帮一下吗
然后我用了encode转为utf-8还是不行,被折磨了一下午了,头都大了,请问有大哥能帮一下吗

学习爬虫时候'ascii' codec can't encode characters报错,百度各种方法都试过了,测试后发现是ascii转不了utf-8

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答
 luyangever 2020-01-06 16:18关注
luyangever 2020-01-06 16:18关注1.头部加#coding:utf-8
2.增加import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)
3.建议你别再win上跑,如果在win上跑,先decode('gbk')再encode('utf-8'),如果gbk不行尝试下ISO-8859-1解决 无用评论 打赏举报 分享
- 2022-06-23 13:56回答 2 已采纳 打开你的浏览器,复制User-Agent后面的
- 2019-08-29 11:02回答 1 已采纳 在linux系统中输入export LANG=en_US.UTF-8,将编码设置为这个就不在出错了 之前的编码为LANG=zh_CN.UTF-8 可以通过locale查询Linux系统的编码方式
- 2022-04-04 11:44
 UnicodeDecodeError: 'utf-8' codec can't decode byte 0x89 in position 0: invalid start byte
flask
python
回答 2 已采纳 不是应该用二进制模式传吗 with open(image_loca_path,"rb") as f:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x89 in position 0: invalid start byte
flask
python
回答 2 已采纳 不是应该用二进制模式传吗 with open(image_loca_path,"rb") as f: - 2019-04-17 14:37HLYJJ的博客 1是改转码,2是因为你怕取得网页有做反爬处理,例如网页默写元素的编码...这是编码问题 查看python默认编码格式,如果不是utf-8,将python默认编码格式改为utf-8 或者在写入的时候转码: 又或者读取网页的时候 ...
- 2020-02-23 12:07回答 3 已采纳 我看了你的网站 ``` ``` 
- 2022-10-15 11:08 储存txt文件时报错'gbk' codec can't encode character '\u200b' in position 164: illegal multibyte sequence
python
回答 2 已采纳 Py文件头加个试试 # coding=utf-8 打开文件加 file1 = open('./学术预告.txt','a',encoding='utf-8')
- 2022-03-05 20:05回答 2 已采纳 改英文状态下的问号,一看就是中文的,而且逻辑有其他问题可以继续交流~
- 2019-11-02 00:30江湖一点雨的博客 python3爬虫报错UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 45-47: ordinal not… 今天用python在pycharm中搞爬虫的时候,在公司电脑上运行还好好的,拿回家以后妈蛋就死活用不了啦...
- 2022-10-20 17:16回答 1 已采纳 encode需要一个字符串你给了字典啊,把字典 json.dumps(你的字典)一下
- 2023-03-09 21:34回答 1 已采纳 你写了多个数据在一个文件里,但你这个不是 json 的标准格式,一个标准的 json 只能有一个值,你这个应该定义成数组格式,即最前边加个 [ ,最后加个 ] 就可以了
- 2018-08-18 19:58回答 1 已采纳 After literally hours of looking for answer and not finding anything (nothing worked for me) I fig
- CrazyCosin的博客 一、问题背景 ...1.首先服务端发送特殊字符的时候,json dumps的时候要指定ensure_ascii为False,不编码。保留原字符。 2.这里其实有个标准输出问题,客户端拿到传输的字符,json loads 但是emoji或者.
- 2012-08-07 09:54回答 1 已采纳 try this for the software #2 iconv("UTF-8", "CP437", $this->_output); Extended ASCII is not
- 2019-05-07 16:49做一个安静的小爬虫的博客 python 【print中文字符串编码问题】 " 'ascii' codec can't encode characters in position......." python 查询当前环境下默认字符编码1.当前文件的编码格式2. 当前系统使用的默认编码3. 标准输出默认编码 针对...
- 2023-01-17 21:22
 已解决UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-3: ordinal not in range(1袁袁袁袁满的博客 已解决UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-3: ordinal not in range(128)
已解决UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-3: ordinal not in range(1袁袁袁袁满的博客 已解决UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-3: ordinal not in range(128) - 2022-12-03 20:37 已解决UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 18-20: ordinal not in range袁袁袁袁满的博客 已解决UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 18-20: ordinal not in range(128)
- 2022-08-24 09:03 已解决UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-1: ordinal not in range(1袁袁袁袁满的博客 已解决(numpy报错)UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-1: ordinal not in range(128)
- ljrshawn的博客 爬虫拼接URL时含有中文,出现’ascii’ codec can’t encode characters in position。。。我的解决方法是直接加入代码urllib.parse.quote(keyword)。 例如: 原代码 url = ...
- 没有解决我的问题, 去提问
悬赏问题
- ¥100 Jenkins自动化部署—悬赏100元
- ¥15 关于#python#的问题:求帮写python代码
- ¥20 MATLAB画图图形出现上下震荡的线条
- ¥15 关于#windows#的问题:怎么用WIN 11系统的电脑 克隆WIN NT3.51-4.0系统的硬盘
- ¥15 perl MISA分析p3_in脚本出错
- ¥15 k8s部署jupyterlab,jupyterlab保存不了文件
- ¥15 ubuntu虚拟机打包apk错误
- ¥199 rust编程架构设计的方案 有偿
- ¥15 回答4f系统的像差计算
- ¥15 java如何提取出pdf里的文字?