关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
笃行之.kiss
2020-01-12 13:45
采纳率: 80%
浏览 3172
首页
Python
已采纳
python-selenium中定位超链接方法find_element_by_link_text和find_elements_by_link_text有什么区别?
python
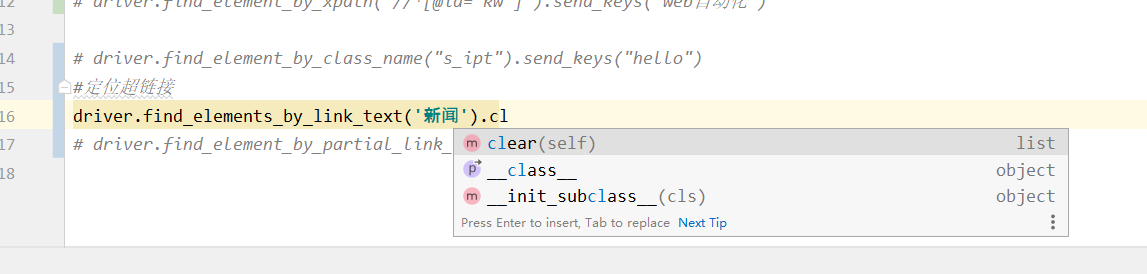
如图find_elements_by_link_tex没有click方法
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
threenewbee
2020-01-12 14:13
关注
顾名思义,带s的是找多个元素,不带s的是找一个元素
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
+
selenium
元素
定位
(一)----driver.find_
element
_by_xxx()
2021-12-07 09:21
@chameleon的博客
元素
定位
... 总共2类8种
方法
driver.find_
element
_by_xxx() 如果匹配到多个,则返回匹配到的第一个。...driver.find_
element
_by_id("IamID").send_keys("通过元素的ID属性来
定位
元素") 2、name 通过元素的name属
深入了解 find_
element
方法
:Web 自动化
定位
元素的核心
2025-07-19 22:53
山烛的博客
总之,find_
element
方法
是 Web 自动化
中
元素
定位
的核心工具,不同的
定位
策略各有优劣,在实际使用
中
,我们需要根据元素的具体特征和网页的实际情况,选择合适的
定位
方式。另外,find_
element
方法
返回的是第一个匹配...
Python
+
selenium
元素
定位
(二) ----driver.find_
elements
_by_xxx()
2021-12-07 19:40
@chameleon的博客
driver.find_
elements
_by_xxx() ** 返回的是一个列表。 列表
中
包含所有匹配到的满足条件的元素。 如果匹配不到,则返回一个空列表。 1、ID 通过元素的id属性来
定位
元素 id 通过元素的id属性来
定位
eles = driver....
Python
+
selenium
元素
定位
----driver.find_
element
_by_xxx()
2023-06-12 21:43
测试老油条的博客
打开开发者工具:F12 或者是点击鼠标右键选择 检查 按钮。总共2类8种
方法
如果匹配到多个,则返回匹配到的第一个。如果匹配不到,则抛出NoSuch
Element
Exception异常(报错)。
【第二天】零基础入门刷题
Python
-
Selenium
-自动化测试-打开百度的首页搜索B站-By类的八种
定位
方法
-find_
element
方法
-send_keys
方法
2025-01-17 19:42
Long_poem的博客
第一天练习打开Firefox浏览器实例和打开Chrome浏览器实例-进入百度的首页第二天练习用Chrome浏览器实例-在百度的首页上搜索B站提示:以下是本篇文章正文...,和八种By类
定位
的
方法
,find_
element
方法
,send_keys
方法
。
Python
+
selenium
元素
定位
(三),By
方法
查找元素----driver.find_
element
(By.XXX, “selector”)
2021-12-08 18:54
@chameleon的博客
By
方法
查找元素 from
selenium
.webdriver.common.by import By 2类8种 driver.find_
element
(By.XXX, “selector”) 如果匹配到多个,则返回匹配到的第一个。 如果匹配不到,则抛出NoSuch
Element
Exception异常...
python
3+
selenium
4自动化测试-元素
定位
之find_
element
()-基础篇4
2021-05-21 22:58
谜城醉梦的博客
而要想完成元素
定位
,
Selenium
WebDriver为我们提供了多种元素选择器,其
中
,
定位
单个元素使用
方法
find_
element
(),包括: 1、通过ID属性
定位
一般来说,如果需要
定位
的元素的ID属性可用、独特且始终可预知的,使用...
Python
+
selenium
元素
定位
(四),By
方法
查找元素----driver.find_
elementS
(By.XXX, “selector”)
2021-12-08 19:03
@chameleon的博客
By
方法
查找元素 from
selenium
.webdriver.common.by import By driver.find_
elementS
(By.XXX, “selector”) 返回的是一个列表,如果匹配不到会怎么样? 如果匹配不到,则返回一个空列表。 1、id 通过元素的id...
find_
element
_by_
link
_
text
()函数
2024-08-20 11:06
渊途的博客
find_
element
_by_
link
_
text
("链接文字") #链接文字在页面
中
一般都是唯一的,所以这个方式可以精确查找到元素。1.在
超链接
定位
里,会返回第一个文本属性匹配的元素,如果没有元素匹配,会抛出NoSuch
Element
Exception...
python
+
selenium
元素
定位
5--
link
_
text
定位
2020-05-27 22:20
Carry.lili的博客
语法:driver.find_
element
_by_
link
_
text
("
超链接
的全部文本类容") 注意:参数一定是
超链接
的全部文本,包含空格和字符 2、看图举例(1、匹配所有
超链接
所有文本。2、匹配部分文本): import time from
selenium
...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享


