1、问题描述:
学习Python操作word文件,使用render()方法时报错ValueError: can only parse strings。
2、相关代码
# _*_ encoding:utf-8 _*_
from docxtpl import DocxTemplate
data_dic = {
't1':'燕子',
't2':'杨柳',
't3':'桃花',
't4':'针尖',
't5':'头涔涔',
't6':'泪潸潸',
't7':'茫茫然',
't8':'伶伶俐俐',
}
doc = DocxTemplate("/test/test.doc") #加载模板文件
doc.render(data_dic) #填充数据
doc.save("/test/target.doc")
3、模板信息:
{{r t1}}去了,有再来的时候;{{r t2}}枯了,有再青的时候;{{r t3}}谢了,有再开的时候。但是,聪明的,你告诉我,我们的日子为什么一去不复返呢?——是有人偷了他们罢:那是谁?又藏在何处呢?是他们自己逃走了罢:现在又到了哪里呢?
我不知道他们给了我多少日子;但我的手确乎是渐渐空虚了。在默默里算着,八千多日子已经从我手中溜去;像{{r t4}}上一滴水滴在大海里,我的日子滴在时间的流里,没有声音,也没有影子。我不禁{{r t5}}而{{r t6}}了。
去的尽管去了,来的尽管来着;去来的中间,又怎样地匆匆呢?早上我起来的时候,小屋里射进两三方斜斜的太阳。太阳他有脚啊,轻轻悄悄地挪移了;我也{{r t7}}跟着旋转。于是——洗手的时候,日子从水盆里过去;吃饭的时候,日子从饭碗里过去;默默时,便从凝然的双眼前过去。我觉察他去的匆匆了,伸出手遮挽时,他又从遮挽着的手边过去,天黑时,我躺在床上,他便{{r t8}}地从我身上跨过,从我脚边飞去了。等我睁开眼和太阳再见,这算又溜走了一日。我掩着面叹息。但是新来的日子的影儿又开始在叹息里闪过了。
4、报错信息:

5、相关依赖包版本
doc 0.1.0
docx 0.2.4
docxtpl 0.6.3
lxml 3.2.1
Jinja2 2.10.3
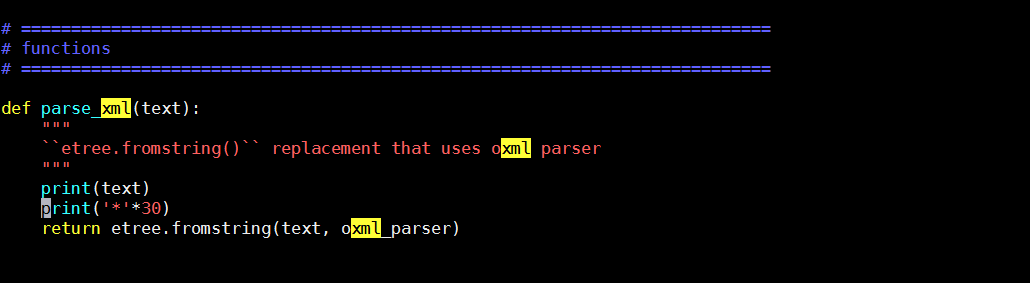
6、我尝试更换了lxml的版本发现报错信息一样。我又尝试跟踪错误,在这个文件里:

打印了一下text:
发现有一步text为None:
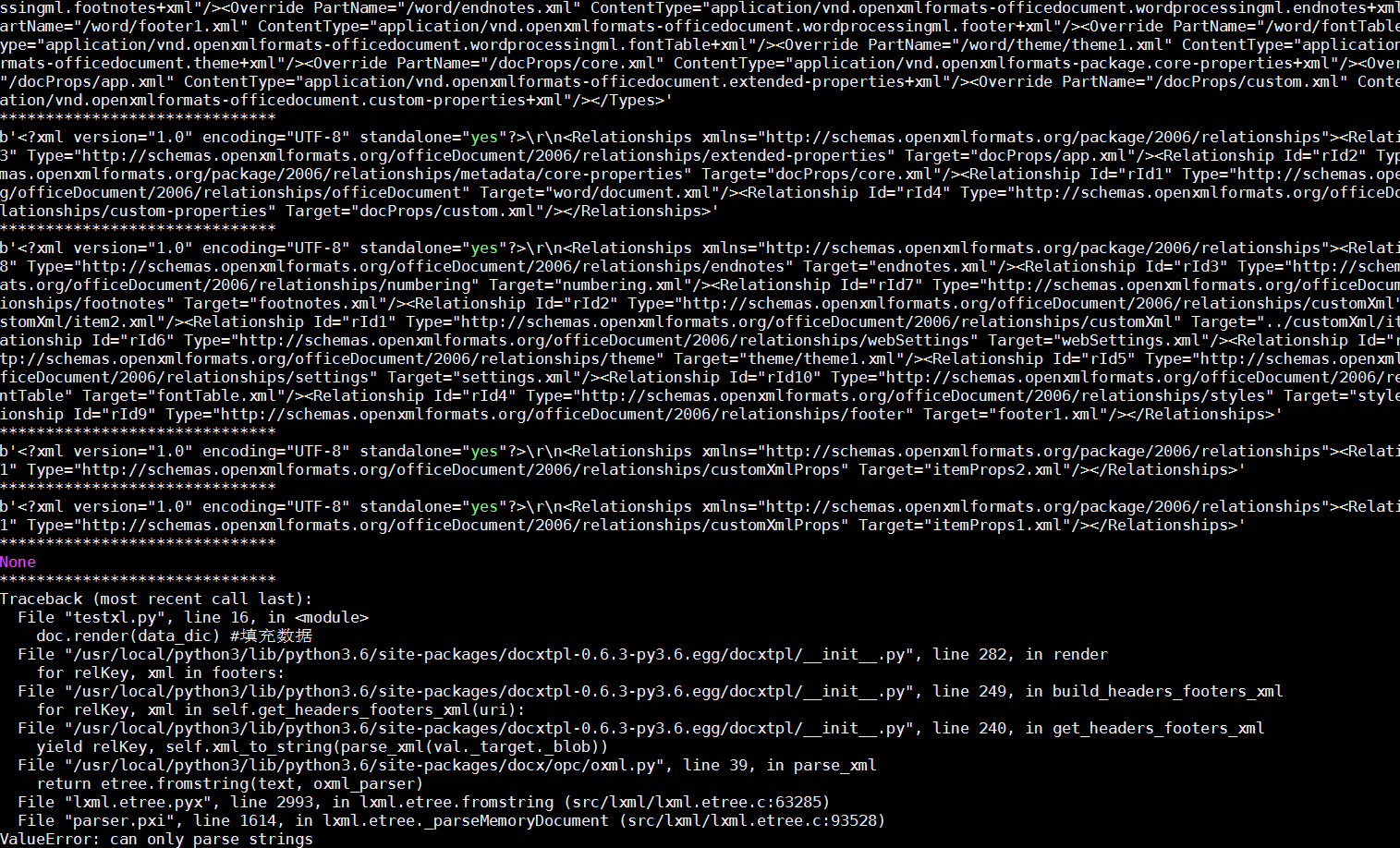
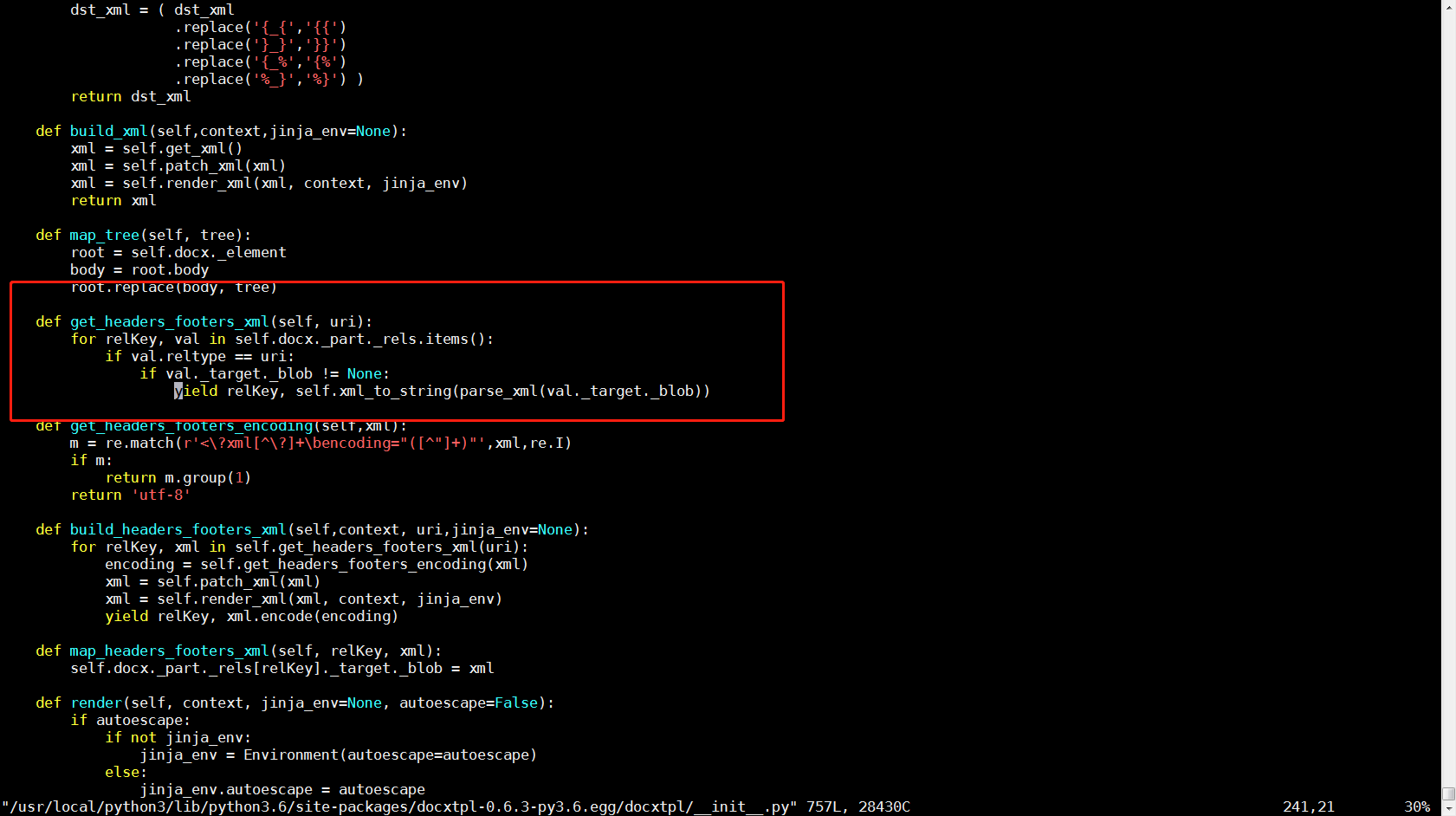
7、所以想问一下有没有大佬遇到并解决过这个问题,怎么解决这个问题。救救一下小萌新吧,还有就是val._target._blob这个变量里存的是什么数据,为什么会出现None的情况?谢谢大佬的指点!
8、追加:
问题暂时得到了解决,我在get_headers_footers_xml这个函数里添加了不为空的判断if val._target._blob != None:yield relKey, self.xml_to_string(parse_xml(val._target._blob)) 就不再报错并且成功写入到目标文件里,但是我仍然不清楚这是不是依赖包本身的BUG。如果有大佬知道的话请指点我一下。如果也有遇到这个问题的朋友,可以试一试我这个方法暂时解决一下。下面是我修改的图片: