
最近在学hadoop,租了一台百度云服务器部署hadoop,启动了NameNode和DataNode还有ResourceManager,在配置完mapred-site.xml后打算启动JobHistoryServer进程看看工作记录,但是配置完ip地址后不是启动成功但打不开history,就是启动失败具体看一下截图:
这张图配置的是我的服务器的ip地址,目前只有一台:
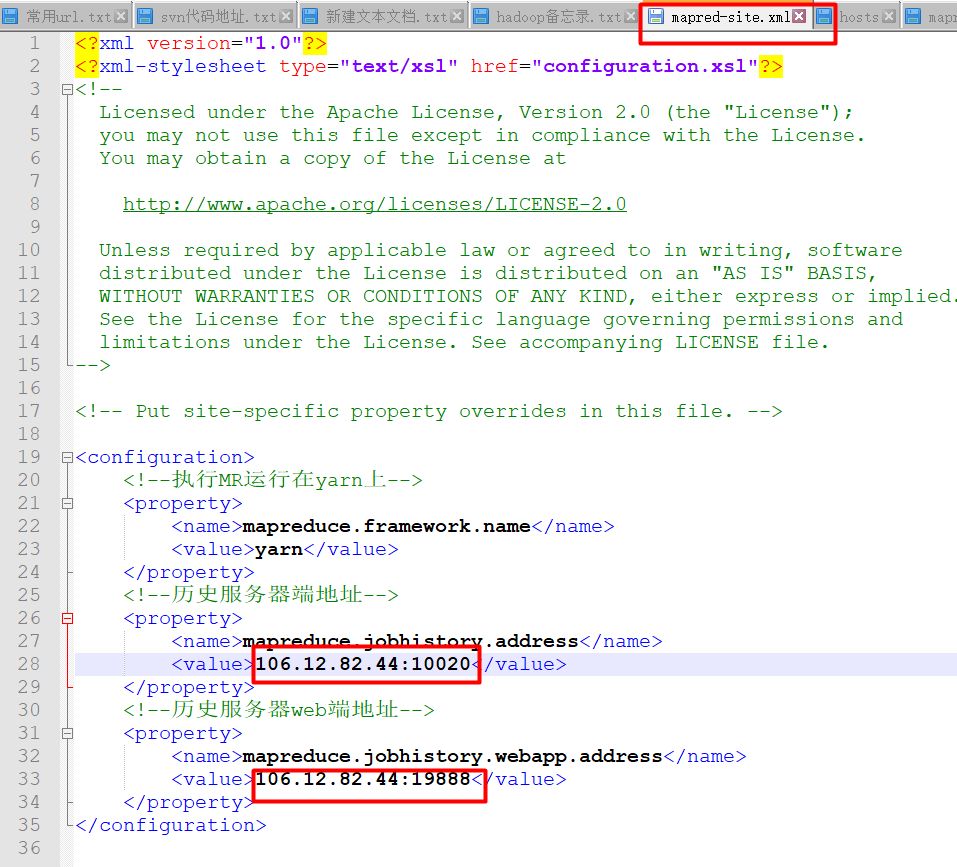
配置完后启动日志里会报错,之后进程就退掉了:
报这个错:是端口号被占用:
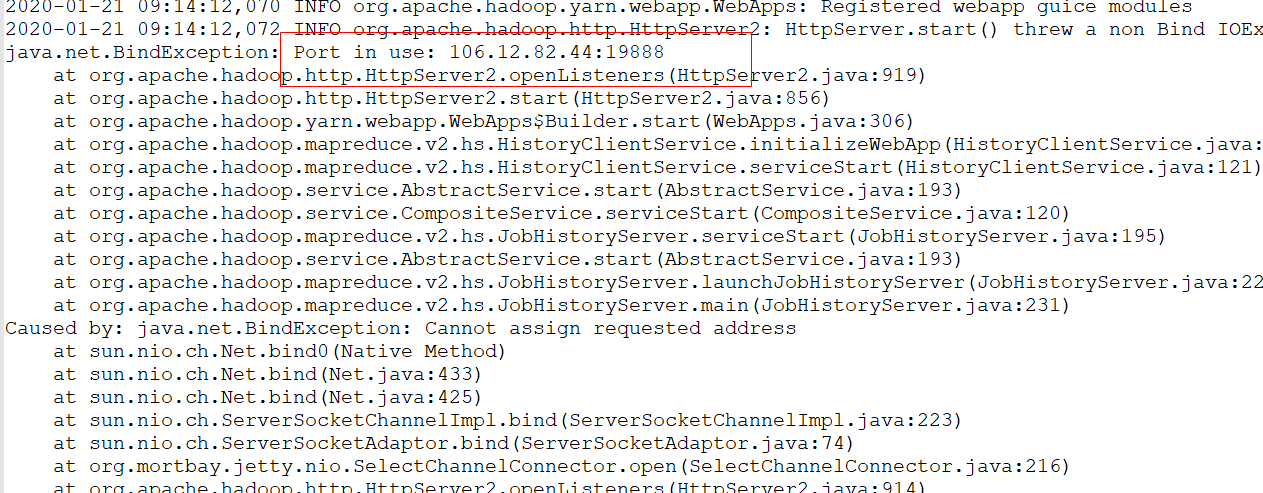 :
:
但是我查看这个端口号没有被占用(其他进程已经启动):
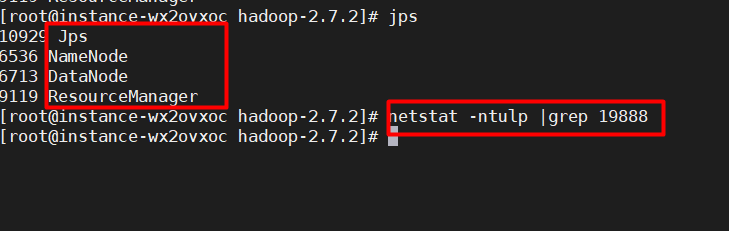 :
:
如果把mapred-site.xmlwe文件里的ip改成下图后就可以成功启动JobHistoryServe进程:
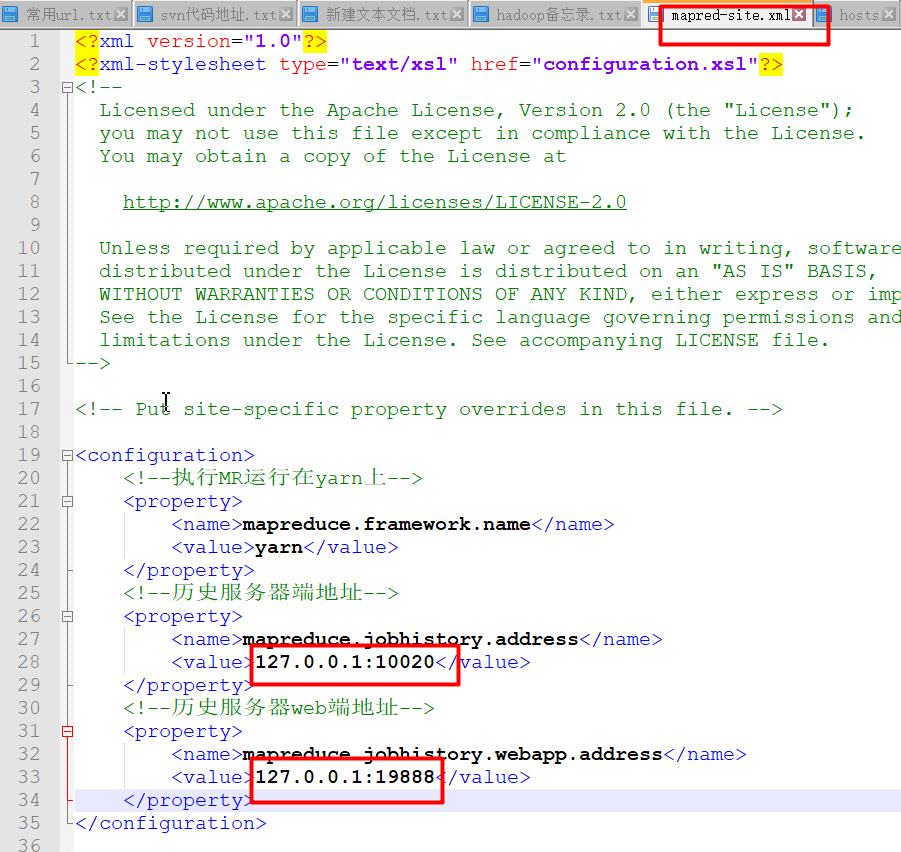 :
:
进程已经启动了,日志里没有报错:
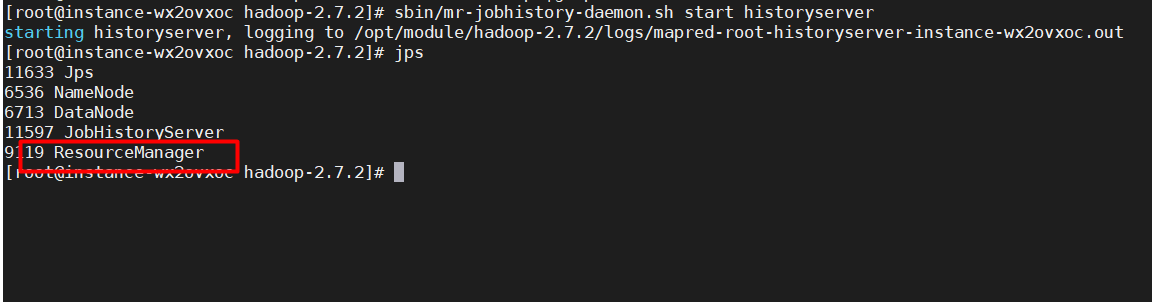 :
:
但是点击history后查看不了工作记录:下图
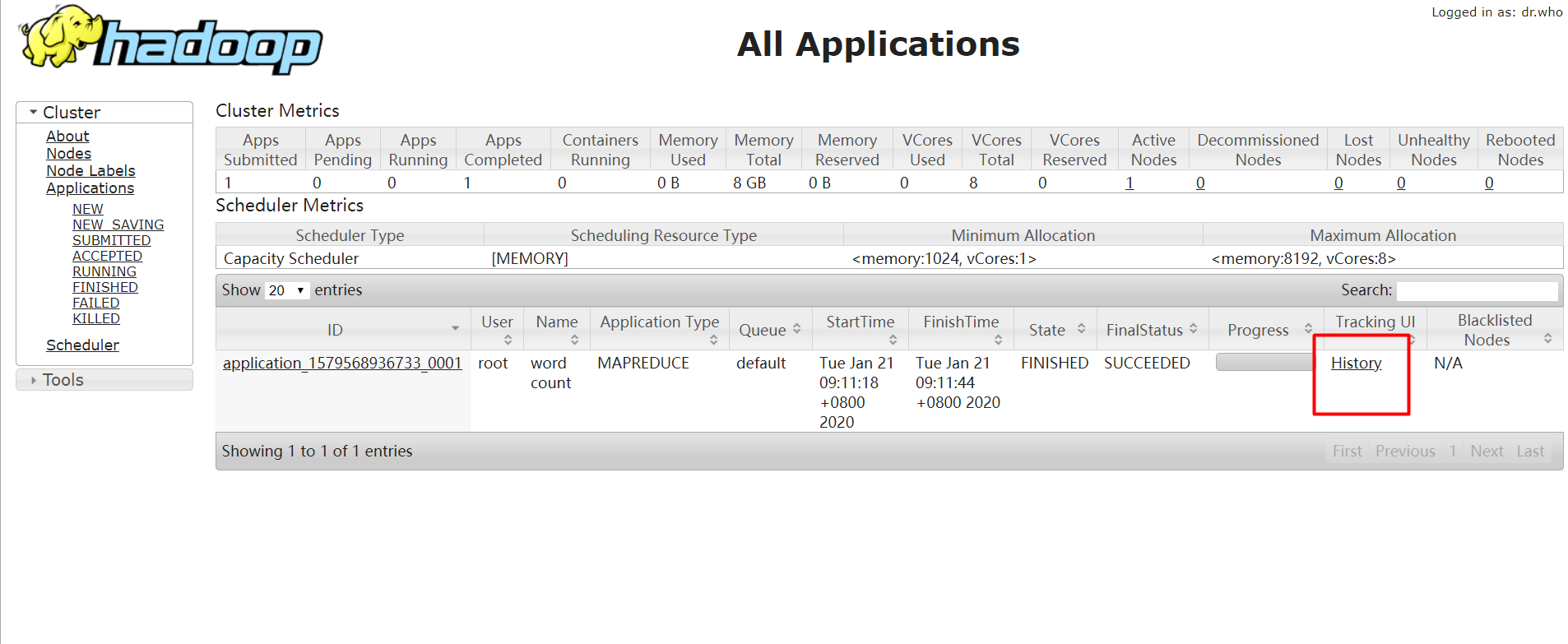 :
:
这是点击history后拒绝访问了:
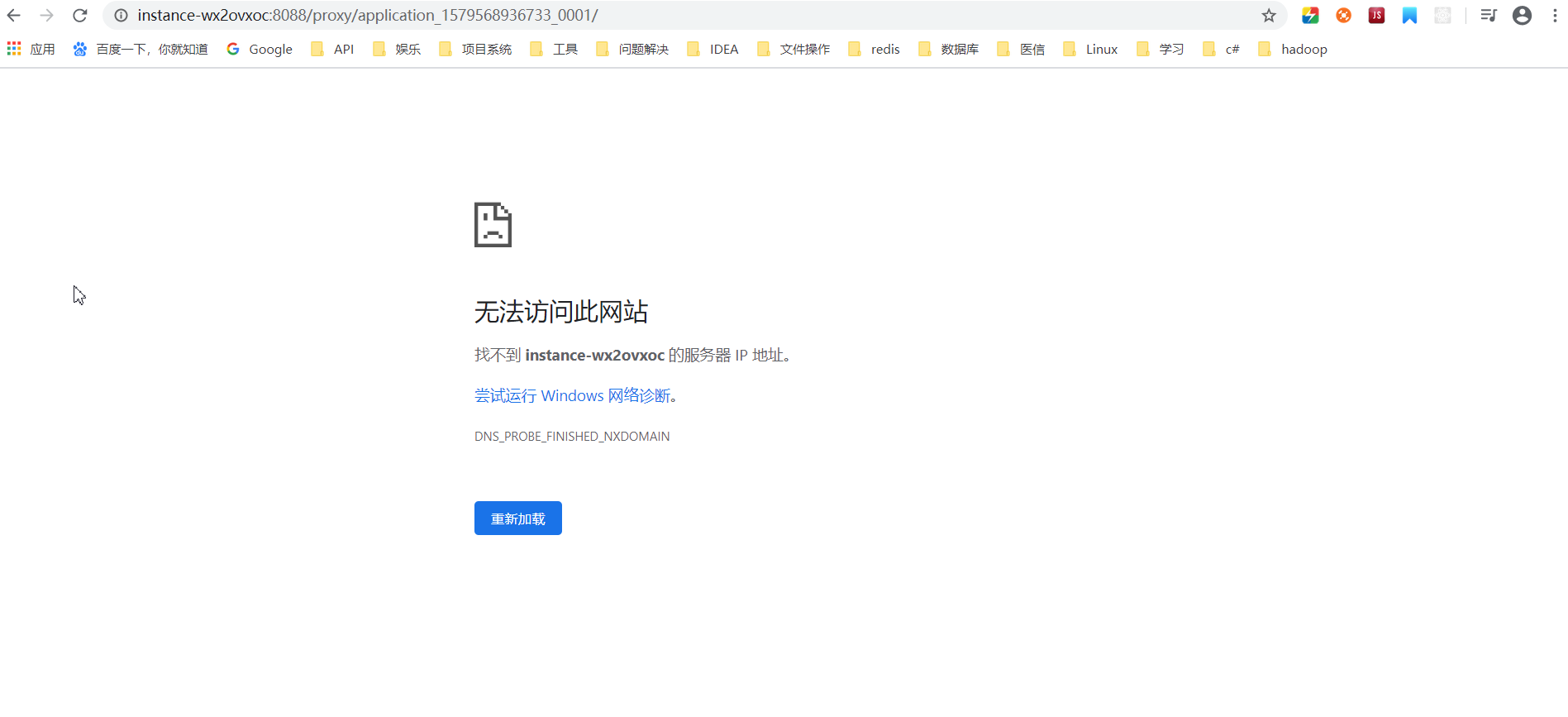 :
:
我也想过是不是服务器hosts文件的问题,按照下面的配置还是不对(在mared-site.xml中把ip改为hadoop44启动不了):
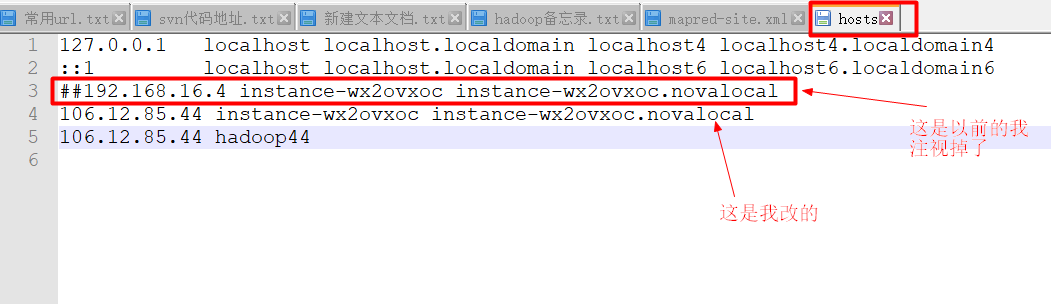 :
:
所以这是我遇到的问题,有没有大神解决一下,谢谢





