
打算在WIndows 10环境配置一下Spark,跟着网上的教程一步一步走到最后,执行spark-shell也成功进入Scala环境
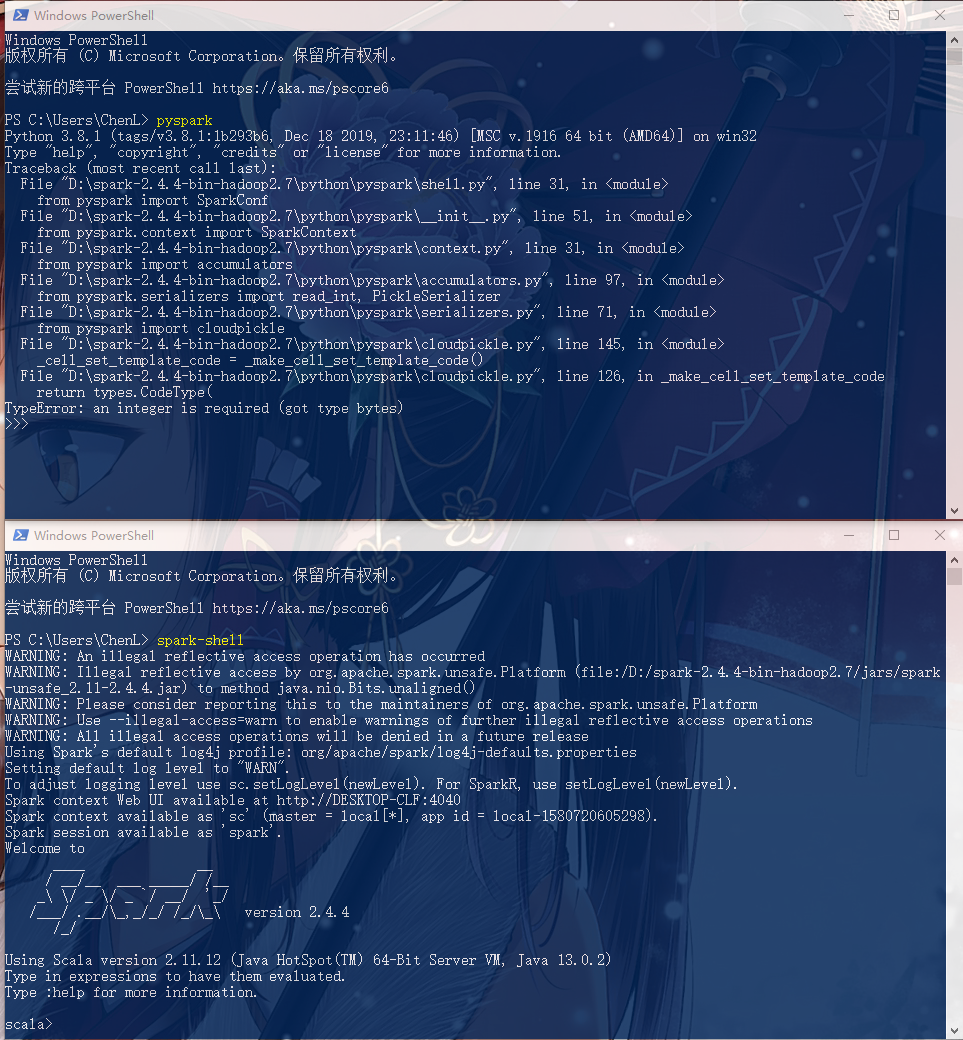
但是执行pyspark却提示TypeError: an integer is required (got type bytes)
完整信息:
Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
Traceback (most recent call last):
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\shell.py", line 31, in <module>
from pyspark import SparkConf
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\__init__.py", line 51, in <module>
from pyspark.context import SparkContext
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\context.py", line 31, in <module>
from pyspark import accumulators
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\accumulators.py", line 97, in <module>
from pyspark.serializers import read_int, PickleSerializer
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\serializers.py", line 71, in <module>
from pyspark import cloudpickle
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\cloudpickle.py", line 145, in <module>
_cell_set_template_code = _make_cell_set_template_code()
File "D:\spark-2.4.4-bin-hadoop2.7\python\pyspark\cloudpickle.py", line 126, in _make_cell_set_template_code
return types.CodeType(
TypeError: an integer is required (got type bytes)
请问如何解决这个问题?是不是Python版本太高了?






