
直接上图
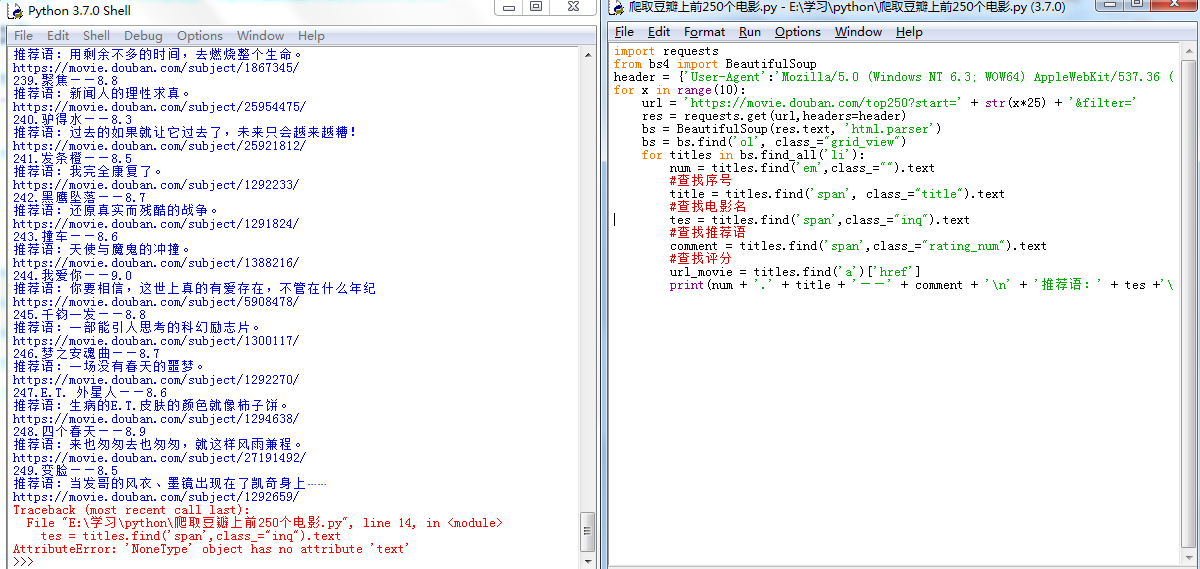
前249个没问题,循环来的为什么最后一个就有问题?
最后一步不肯走报错了
然后我试了一下协程爬取:
from gevent import monkey
monkey.patch_all()
import requests,time,gevent
from gevent.queue import Queue
start=time.time()
url_list={'https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/'
}
work=Queue()
for url in url_list:
work.put_nowait(url)
def pa():
while not work.empty():
url=work.get_nowait()
res=requests.get(url)
print(url,work.qsize(),res.status_code)
task_list=[]
for i in range(2):
task=gevent.spawn(pa)
task_list.append(task)
gevent.joinall(task_list)
end=time.time()
print(end-start)
错误就一大堆了。
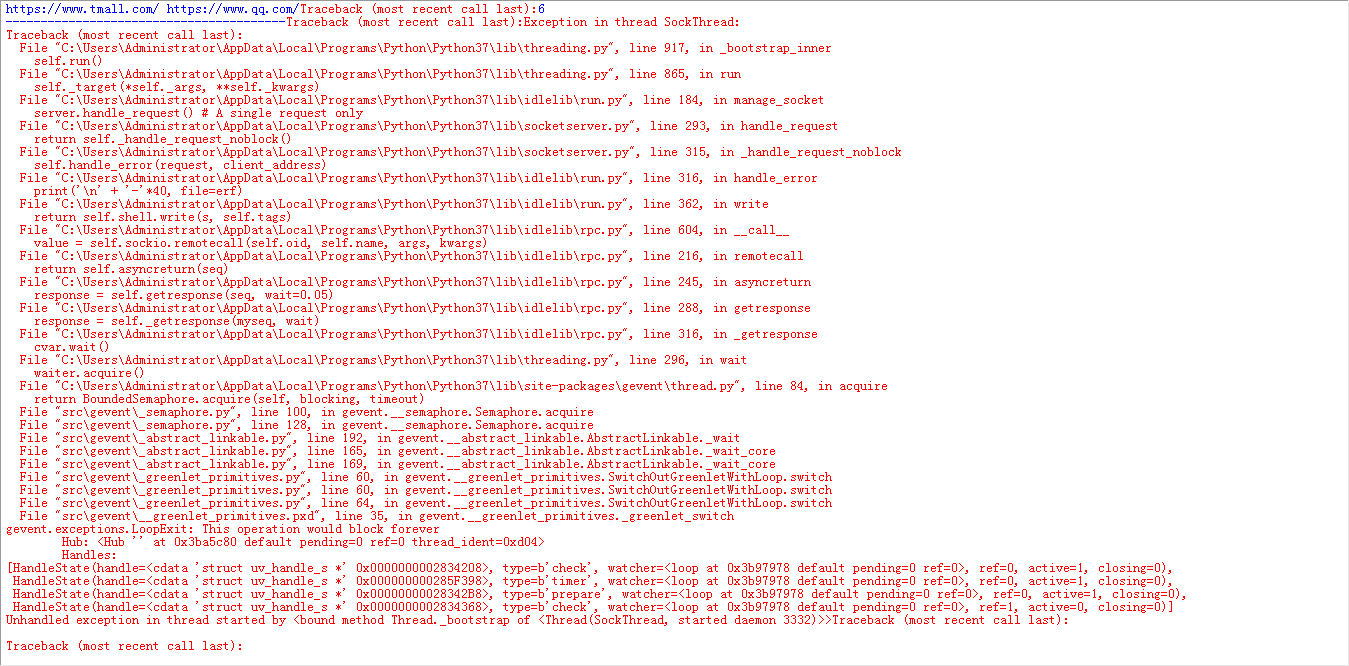
简单的爬取就可以过:
import requests
from bs4 import BeautifulSoup
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url='http://www.weather.com.cn/weather/101281905.shtml'
res=requests.get(url,headers=headers)
res.encoding='utf-8'
bs=BeautifulSoup(res.text,'html.parser')
lis=bs.find(class_='t clearfix').find_all('li')
for li in lis:
day=li.find('h1')
how=li.find(class_='wea')
num=li.find(class_='tem')
print('日期:'+day.text+'\n天气:'+how.text+'\n温度:'+num.text+'\n---------------')

已试,用selenium没发现问题
然而当我运行以下代码时:
from gevent import monkey
monkey.patch_all()
import gevent,requests, bs4, csv
from gevent.queue import Queue
work = Queue()
url_1 = 'http://www.boohee.com/food/group/{type}?page={page}'
for x in range(1, 4):
for y in range(1, 4):
real_url = url_1.format(type=x, page=y)
work.put_nowait(real_url)
url_2 = 'http://www.boohee.com/food/view_menu?page={page}'
for x in range(1,4):
real_url = url_2.format(page=x)
work.put_nowait(real_url)
print(work)
结果是一片空





