1.编译错误 到99%
2.结果如图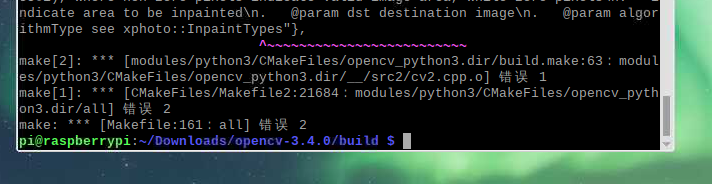
3.错误问题#make错误,退出
make[2]: *** [modules/python3/CMakeFiles/opencv_python3.dir/build.make:56: modules/python3/CMakeFiles/opencv_python3.dir/__/src2/cv2.cpp.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:21149: modules/python3/CMakeFiles/opencv_python3.dir/all] Error 2
make: *** [Makefile:138: all] Error

python3.4.0安装opencv出现问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

- 2019-08-11 12:57回答 4 已采纳 我和小伙伴解决了这个问题,我们的设备是树莓派3B。 方案一:如果你不需要opencv4.X的版本。先需要安装opencv的依赖库,再使用sudo apt-get install python3-op
- 2022-09-01 10:20回答 1 已采纳 你应该已经安装过了吧,你试试输入命令vue --version看看是不是已经有了
- 2019-07-16 09:38回答 1 已采纳 首先String类中只有两个变量cstr_,len_。cstr就是指向buffer的指针,len_维护buffer的size。 由于OpenCV中采用了share buffer来优化内存使用,当
- 2020-11-24 06:04weixin_39797686的博客 $ sudo pip install opencv-python$ sudo pip install opencv-contrib-python参考下:python作业毕设:安装人工智能图像处理工具OpenCVzhuanlan.zhihu.compython版本安装适合所有平台:$ sudo pip install opencv-...
- 2022-04-07 09:28回答 3 已采纳 先配置再安装 npm config set registry https://registry.npm.taobao.org
- 2023-04-15 09:26回答 4 已采纳 基于Monster 组和GPT的调写: 代码和配置文件,似乎没有明显的问题。下面是可能会导致问题的几个方面: 安装包损坏或签名问题你已经排除了这种可能性,因为这三个 APK 都能够单独安装。 文件路径
- 回答 1 已采纳 检查一下你所使用的仓库中是否有这个依赖,中央仓库中是有这个依赖的,应该不是拼写错误。或者就是本地Maven处在离线模式,而本地仓库中又没有这个依赖。都检查下吧,有帮助帮忙点个采纳,谢谢~
- 2020-12-14 13:40weixin_39625563的博客 子豪兄教你在树莓派上安装OpenCV注意,如要换源,只能按本博客换源方法其他会出错本文介绍了如何在树莓派上安装分别运行在Python2和Python3的OpenCV。运行在Python2上的OpenCV安装非常简单,几行命令即可搞定。运行...
- 2022-02-11 15:49回答 3 已采纳 这个应该是源码问题,你可以按照下面的修改一下源码参考一下:https://blog.csdn.net/weixin_43575322/article/details/115022664
- 2023-03-20 13:41回答 7 已采纳 你好,我可以远程
- 2022-07-07 16:53回答 1 已采纳 这些都是警告 ,不影响 正常运行吧,不用理会
- 2022-04-02 22:26opencv_python-3.4.0-cp36-cp36m-win_amd64.whl,适用于python3.6,window 64位。上传它是因为原下载链接打不开了。【opencv_python-3.4.0-cp36-cp36m-win_amd64.whl】,用于python安装opencv模块。
- 2022-09-25 21:02回答 8 已采纳 npm i --legacy-peer-deps然后执行npm install 问题解决
- 2022-10-20 21:22flypig哗啦啦的博客 OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和...本文主要介绍在debian10系统中安装指定版本的opencv,由于OpenCV3中使用SIFT和SURF特征提取。
- 2021-02-02 07:003D视觉工坊的博客 点击上方“3D视觉工坊”,选择“星标”干货第一时间送达本文主要介绍如何在ARM开发板上从源码编译安装OpenCV和OpenCV contrib。OpenCV的源码主要有下面两部分:git...
- 2022-10-20 14:13AI吃大瓜的博客 Ubuntu18.04安装opencv和opencv_contrib,源码编译opencv和opencv_contrib,安装opencv_contrib
- 2023-07-13 16:13小秋 AI SLAM入门实战的博客 找到 opencv-3.4.8/samples/cpp/example_cmake 目录下,官方已经给出了一个cmake的example,我们可以拿来测试下。把opencv_contrib移到opencv中 并在opencv中新建build文件夹。即可看到打开了摄像头,在左上角有一个...
- 2022-05-07 18:03Eric_Downey的博客 一、获取源代码 git clone https://github.com/opencv/opencv.git git clone https://github.com/opencv/opencv_contrib.git ...三、安装依赖 sudo apt-get install build-essential sudo apt-get ...
- 2023-03-17 11:28uestc_j的博客 然后去https://github.com/xianyi/OpenBLAS下载下来源码编译安装,但我操作完之后还是有版本问题。apt安装的openblas似乎不行,只能自己下载源码编译,很简单,只需要注意提前安装fortran编译器。vgg文件下载错误...
- 2022-12-05 16:56苏格兰飞行员!的博客 pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 安卓adb backup备份应用数据失败
- ¥15 eclipse运行项目时遇到的问题
- ¥15 关于#c##的问题:最近需要用CAT工具Trados进行一些开发
- ¥15 南大pa1 小游戏没有界面,并且报了如下错误,尝试过换显卡驱动,但是好像不行
- ¥15 没有证书,nginx怎么反向代理到只能接受https的公网网站
- ¥50 成都蓉城足球俱乐部小程序抢票
- ¥15 yolov7训练自己的数据集
- ¥15 esp8266与51单片机连接问题(标签-单片机|关键词-串口)(相关搜索:51单片机|单片机|测试代码)
- ¥15 电力市场出清matlab yalmip kkt 双层优化问题
- ¥30 ros小车路径规划实现不了,如何解决?(操作系统-ubuntu)